项目全局使用Kni4j调试工具
首先Auth模块:
微信小程序登录
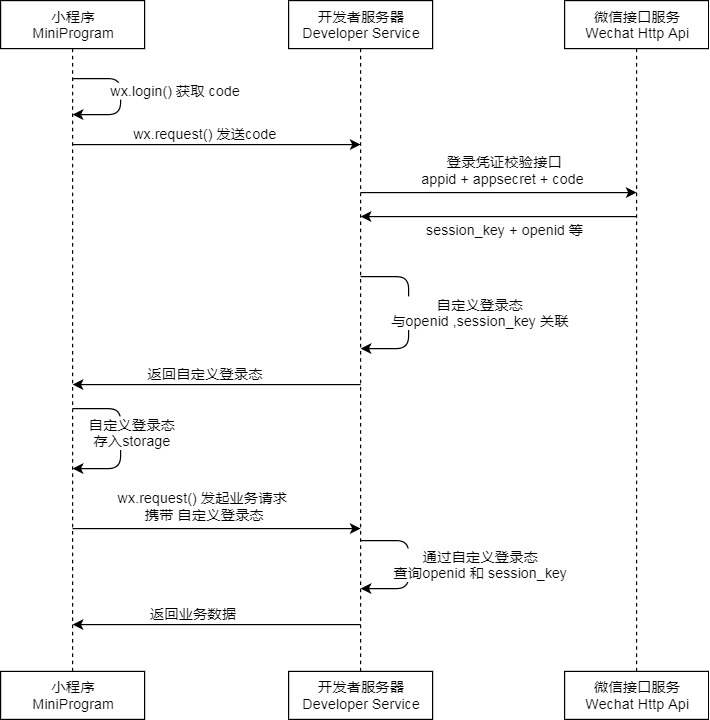
三个端:小程序端,开发者服务器端,微信接口服务端
我们首先通过wx.login()(微信平台集成直接调用即可)获取Code
拿到code之后通过wx.request()发送code到你的开发者服务器后端,后端
发送appid+appsecret+code到微信接口服务,微信接口服务验证成功后
微信将返回以下信息:
{
"openid": "o6_bmjrPTlm6_2sgVt7hMZOPfL2M", // 用户唯一标识(微信开放平台下唯一,openid 是由微信官方提供的)
"session_key": "tiihtNczf5v6AKRyjwEUhQ==", // 会话密钥(用于解密用户敏感信息)
"unionid": "o6_bmasdasdsad6_2sgVt7hMZOPfL" // 当用户绑定了微信开放平台账号时返回
}我们将openid 往数据库里一保存,生成id,然后根据主键id也好,根据openid也好,生成token返回前端,然后前端把token存入storage,然后用户在活动中向后端发送请求时,必须携带此token即可(后端可以校验),成功后返回业务数据就行了!
微信小程序登录代码:
import $http from './utils/request.js'
import { token } from './api/auth.js'
import Storage from './utils/storage.js'
App({
$http,
onLaunch() { //项目启动默认会执行
console.log('小程序启动')
// 展示本地存储能力
const logs = Storage.getLogs() || []
logs.unshift(Date.now())
Storage.setLogs(logs)
// 登录
wx.login({ //调用微信提供的wx.login
success: async res => {
console.log('wx.login 成功,获取到 code:', res.code)//从res中拿到code
// 发送 res.code 到后台换取 openId, sessionKey, unionId
try {
let loginRes = await token(res.code);//拿到code之后向本地发起请求
console.log('token 请求响应:', loginRes)//后端返回loginRes
if(loginRes && loginRes.code === 200){
Storage.setToken(loginRes.data.tokenName, loginRes.data.tokenValue)//把后端返回的token信息保存到Storage,后期请求都要携带
console.log('token 存储成功')
} else {
console.error('token 请求失败:', loginRes)
}
} catch (error) {
console.error('token 请求异常:', error)
}
},
fail: err => {
console.error('wx.login 失败:', err)
}
})
},
globalData: {
userInfo: null
}
})
由于微信在获取token的时候要用get请求,get请求要跟参数必须用?加&拼接
{
"openid": "o6_bmjrPTlm6_2sgVt7hMZOPfL2M", // 用户唯一标识(微信开放平台下唯一,openid 是由微信官方提供的)
"session_key": "tiihtNczf5v6AKRyjwEUhQ==", // 会话密钥(用于解密用户敏感信息)
"unionid": "o6_bmasdasdsad6_2sgVt7hMZOPfL" // 当用户绑定了微信开放平台账号时返回
}拿到微信返回的数据后可以进行持久化,然后颁发token,这里用的是Sa-toekn
官网:https://sa-token.cc/doc.html#/up/disable
sa-token:
# token 名称(同时也是 cookie 名称)
token-name: aimin-auth-token
# token 有效期(单位:秒) 默认30天,-1 代表永久有效
timeout: 2592000
# token 最低活跃频率(单位:秒),如果 token 超过此时间没有访问系统就会被冻结,默认-1 代表不限制,永不冻结
active-timeout: -1
# 是否允许同一账号多地同时登录 (为 true 时允许一起登录, 为 false 时新登录挤掉旧登录)
is-concurrent: true
# 在多人登录同一账号时,是否共用一个 token (为 true 时所有登录共用一个 token, 为 false 时每次登录新建一个 token)
is-share: false
# token 风格(默认可取值:uuid、simple-uuid、random-32、random-64、random-128、tik)
token-style: uuid
# 是否输出操作日志
is-log: true
配置类:
@Configuration
public class SaTokenConfigure {
/**
* 注册 [Sa-Token全局过滤器]
*
*/
@Bean
public SaServletFilter getSaServletFilter() {
return new SaServletFilter()
// 指定 拦截路由 与 放行路由
.addInclude("/**")
// .addExclude("/test/**")
.addExclude("/public/wx/token")
.addExclude("/test/**")
.addExclude("/doc.html/**")
// 认证函数: 每次请求执行
.setAuth(obj -> {
System.out.println("---------- 进入Sa-Token全局认证 -----------");
// 登录认证 -- 拦截所有路由,并排除/user/doLogin 用于开放登录
SaRouter.match("/**", "/public/wx/token", () -> StpUtil.checkLogin());
// 更多拦截处理方式,请参考“路由拦截式鉴权”章节 */
})
// 异常处理函数:每次认证函数发生异常时执行此函数
.setError(e -> {
System.out.println("---------- 进入Sa-Token异常处理 -----------");
return SaResult.error(e.getMessage());
})
// 前置函数:在每次认证函数之前执行(BeforeAuth 不受 includeList 与 excludeList 的限制,所有请求都会进入)
.setBeforeAuth(r -> {
// ---------- 设置一些安全响应头 ----------处理跨域问题
SaHolder.getResponse()
// 服务器名称
.setServer("sa-server")
// 是否可以在iframe显示视图: DENY=不可以 | SAMEORIGIN=同域下可以 | ALLOW-FROM uri=指定域名下可以
.setHeader("X-Frame-Options", "SAMEORIGIN")
// 是否启用浏览器默认XSS防护: 0=禁用 | 1=启用 | 1; mode=block 启用, 并在检查到XSS攻击时,停止渲染页面
.setHeader("X-XSS-Protection", "1; mode=block")
// 禁用浏览器内容嗅探
.setHeader("X-Content-Type-Options", "nosniff")
;
})
;
}
}
这里我们只需要放行/public/wx/token微信登录接口,登录成功后颁发token,
@RestController
@RequestMapping("/public/wx")
@RequiredArgsConstructor
public class Wxcontroller {
private final WxService wxService;
@RequestMapping("/token")
// 微信发送过来一个code
public Result token(String code)
{
Jscode2SessionResult jscode2SessionResult = wxService.wxLogin(code);
// 假设数据库存储成功拿到id代表登录成功
StpUtil.login(1);//为用户分配一个 token 并建立会话
// 获取token信息
SaTokenInfo tokenInfo = StpUtil.getTokenInfo();
String tokenName = tokenInfo.getTokenName();
String tokenValue = tokenInfo.getTokenValue();
return Result.success(tokenInfo);
}SaTokenInfo tokenInfo = StpUtil.getTokenInfo();
String tokenName = tokenInfo.getTokenName();
String tokenValue = tokenInfo.getTokenValue();
这一部分,拿到name和值就可以
@GetMapping("/check")
public String userJoin2() {
try {
StpUtil.checkLogin();
} catch (Exception e) {
return "err:请登录!";
}
return "success";
}这是测试代码,Sa-token回去coookie,header等去找token,找到后校验,如果不通过则拦截
测试用例:
public Result token(String code)
{
Jscode2SessionResult jscode2SessionResult = wxService.wxLogin(code);
// 假设数据库存储成功拿到id代表登录成功
StpUtil.login(1);//为用户分配一个 token 并建立会话
// 获取token信息
SaTokenInfo tokenInfo = StpUtil.getTokenInfo();
String tokenName = tokenInfo.getTokenName();
String tokenValue = tokenInfo.getTokenValue();
return Result.success(tokenInfo);这个地方StpUtil的getTokenInfo是自动生成的,tokenInfo里面包含TokenName和TokenValue
AI模块:
首先打开SpringAi官网:https://docs.spring.io/spring-ai/reference/api/chat/deepseek-chat.html
<!--把这个文件放入之后用SpringAi就不用加版本号了,它本身不下载任何东西-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>之后我们如果选择deepseek模型:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-deepseek</artifactId>
</dependency>这里不用加版本号
接着我们去配置一下秘钥:
ai:
deepseek:
api-key: *******************
chat:
options:
model: deepseek-chat官方演示Controller:
@RestController
public class ChatController {
private final DeepSeekChatModel chatModel;
@Autowired
public ChatController(DeepSeekChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
var prompt = new Prompt(new UserMessage(message));
return chatModel.stream(prompt);
}
}一个是流式输出,一个是一问一答
其中Prompt是提示词
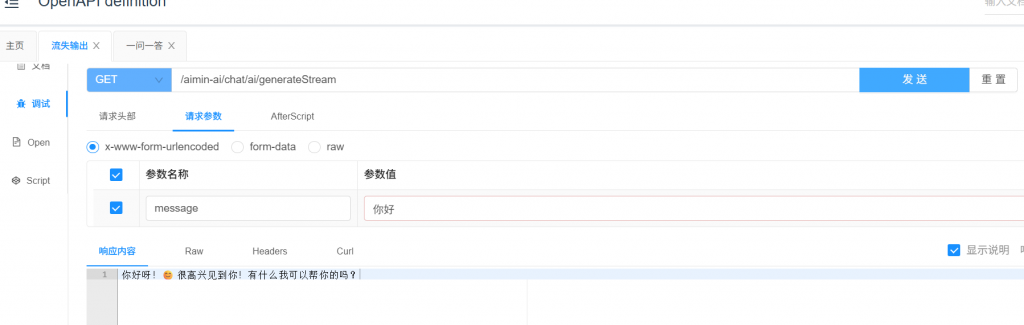
流式输出:
// deepseek流式输出
@GetMapping("/ai/generateStream2")
public String deepSeekReasonerExample() {
DeepSeekChatOptions promptOptions = DeepSeekChatOptions.builder()
.model(DeepSeekApi.ChatModel.DEEPSEEK_REASONER.getValue())
.build();
Prompt prompt = new Prompt("用中文回复,9.11 and 9.8, which is greater?", promptOptions);
ChatResponse response = chatModel.call(prompt);
// Get the CoT content generated by deepseek-reasoner, only available when using deepseek-reasoner model
DeepSeekAssistantMessage deepSeekAssistantMessage = (DeepSeekAssistantMessage) response.getResult().getOutput();
String reasoningContent = deepSeekAssistantMessage.getReasoningContent();
String text = deepSeekAssistantMessage.getText();
return text ;
}如果仅仅使用对话等一些简单的功能,那么private final DeepSeekChatModel chatModel;
够了,但是如果要实现对话,会话记忆等高级功能,那么就需要用
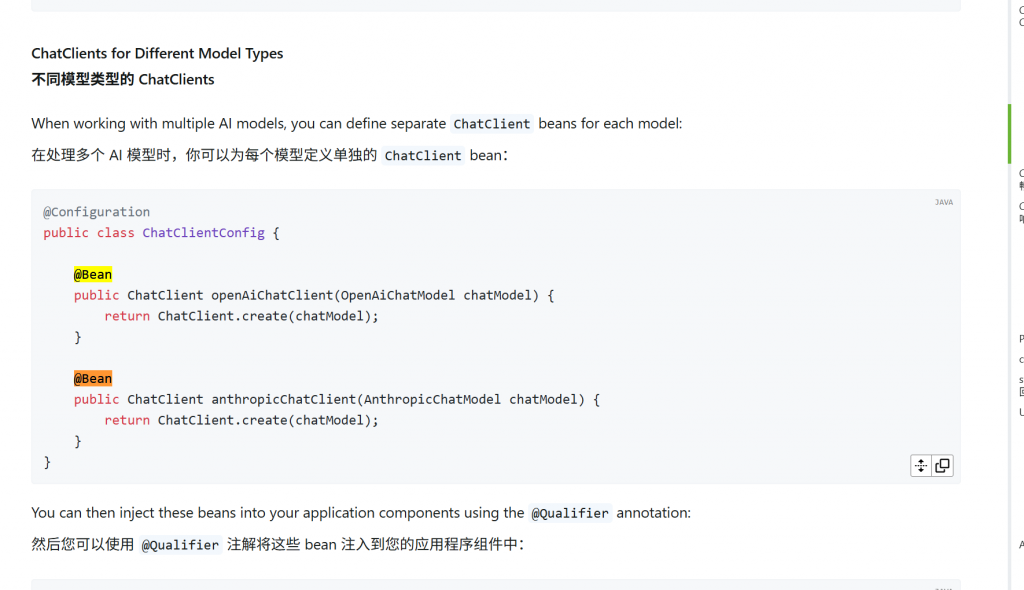
这个API可以声明多个模型,并且可以实现会话记忆功能
官方代码:
ChatMemory chatMemory = ... // Initialize your chat memory store
VectorStore vectorStore = ... // Initialize your vector store
var chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory).build(), // chat-memory advisor
QuestionAnswerAdvisor.builder(vectorStore).build() // RAG advisor
)
.build();
var conversationId = "678";
String response = this.chatClient.prompt()
// Set advisor parameters at runtime
.advisors(advisor -> advisor.param(ChatMemory.CONVERSATION_ID, conversationId))
.user(userText)
.call()
.content();再次我们部署ollama。下载好模型后:

直接启动,命令 ollama run 模型名称
我们在配置类里声明这个moudle:
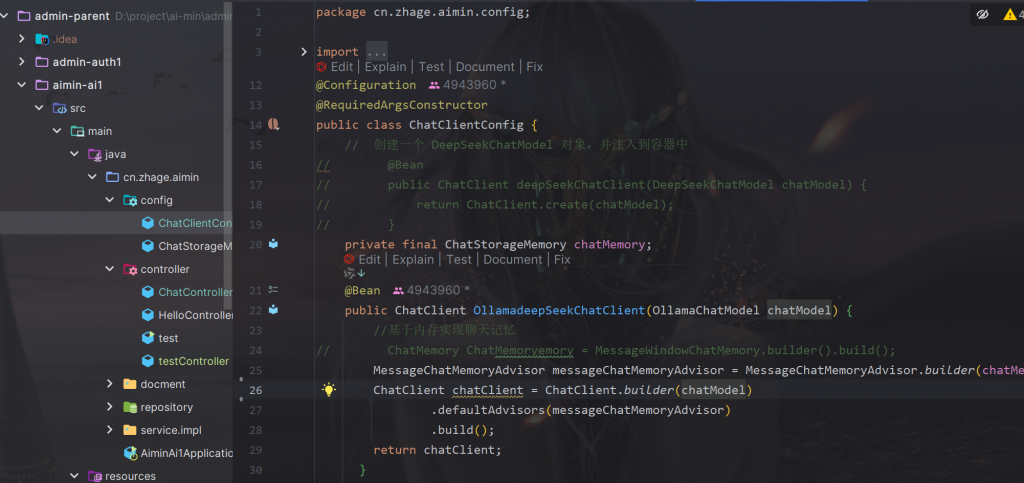
@Configuration
@RequiredArgsConstructor
public class ChatClientConfig {
// 创建一个 DeepSeekChatModel 对象,并注入到容器中
// @Bean
// public ChatClient deepSeekChatClient(DeepSeekChatModel chatModel) {
// return ChatClient.create(chatModel);
// }
private final ChatStorageMemory chatMemory;
@Bean
public ChatClient OllamadeepSeekChatClient(OllamaChatModel chatModel) {
//基于内存实现聊天记忆
// ChatMemory ChatMemoryemory = MessageWindowChatMemory.builder().build();
MessageChatMemoryAdvisor messageChatMemoryAdvisor = MessageChatMemoryAdvisor.builder(chatMemory).build();
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(messageChatMemoryAdvisor)
.build();
return chatClient;
}
}对应controller:
@GetMapping("/ai")
public String generate(@RequestParam(value = "message") String message) {
//得到用户ID,这里假设为1
return chatClient.prompt(message).advisors(advisor -> advisor.param(ChatMemory.CONVERSATION_ID, 1))
.call()//调用模型
.content();//返回内容
// return Map.of("generation", chatModel.call(message));
}这样就可以实现基于内存的聊天记忆功能!
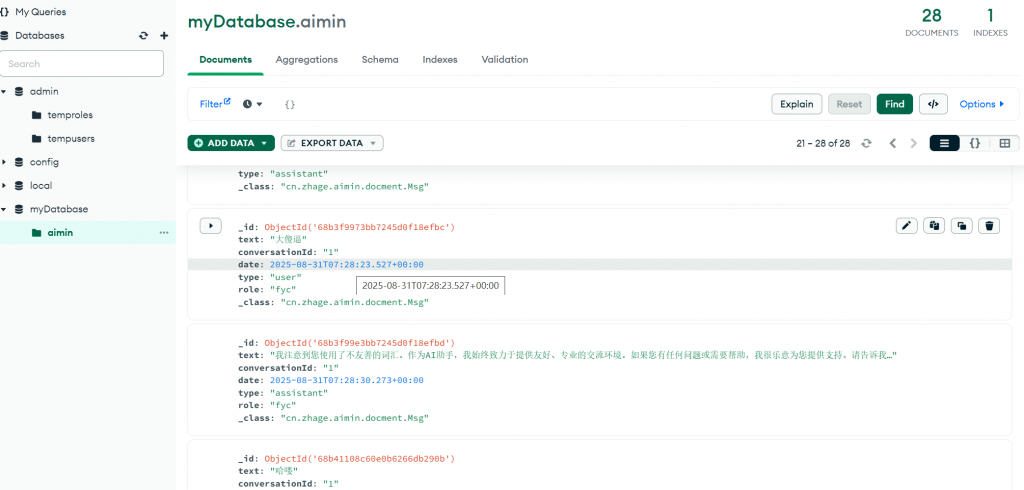
集成Mongodb实现聊天记忆:
在common中创建mongo模块
和ds一样,集成之后,配置一下mongo的配置信息
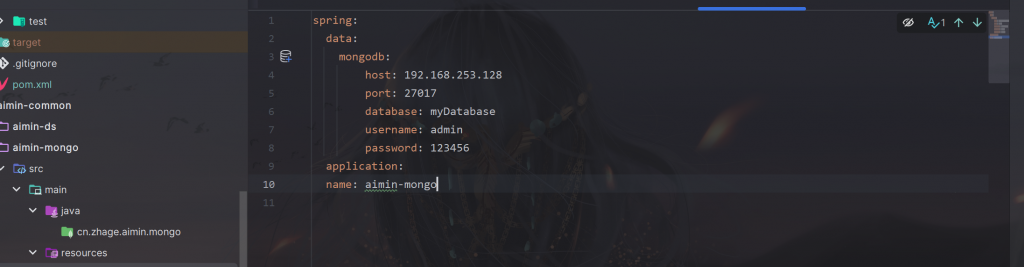
在ai模块中创建msg实体类:
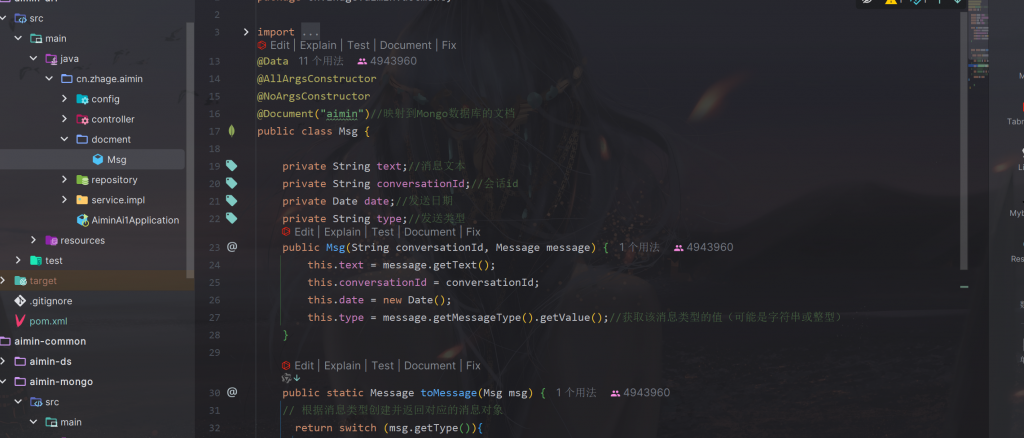

创建一个mapper,这里叫repository(仓库)
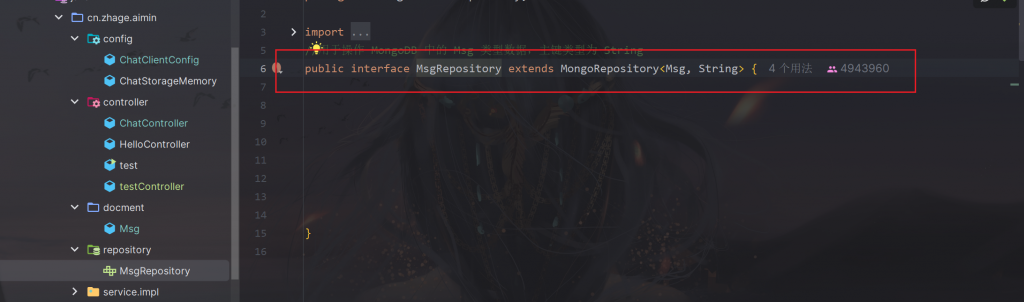
mongo中MongoRepository已经帮我们实现了基础的增删改查
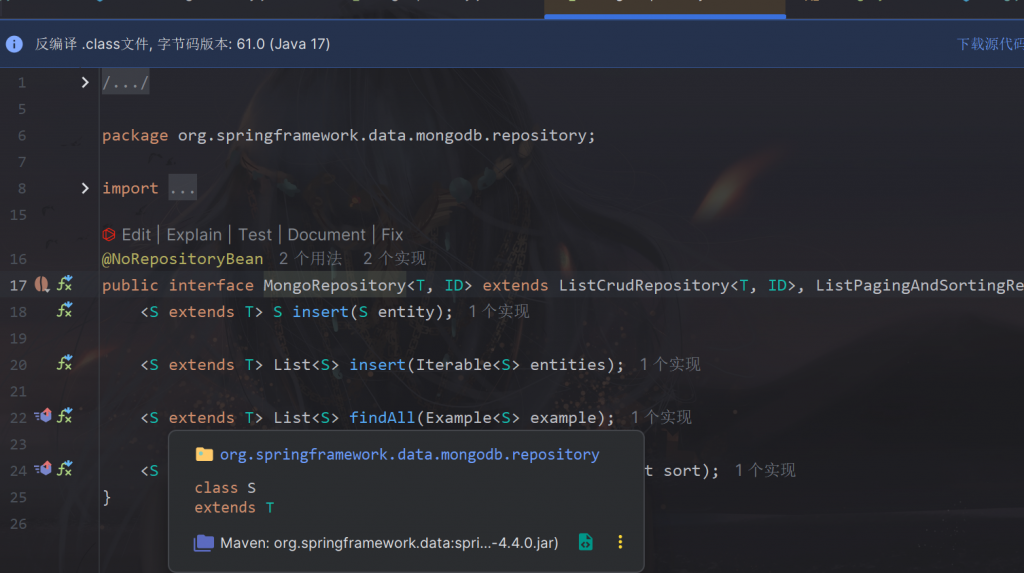
对比:
这里用mongoTemplate去查询mongo里查询:
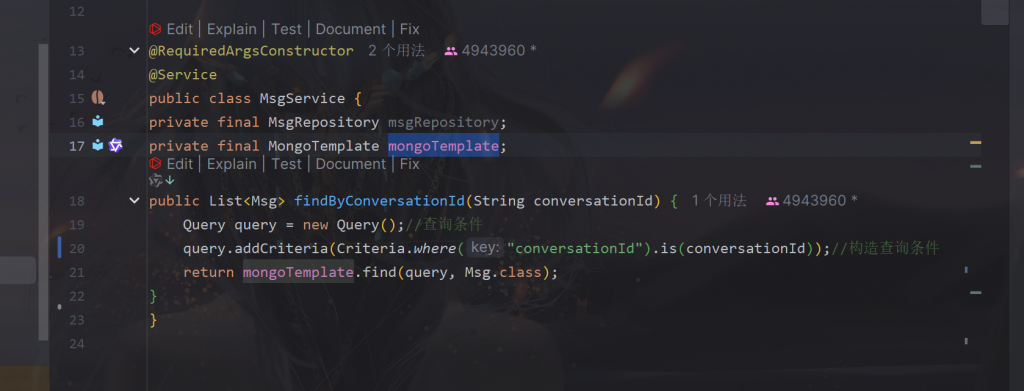
这里实现重写聊天记忆的方法,重写ChatMemory
:
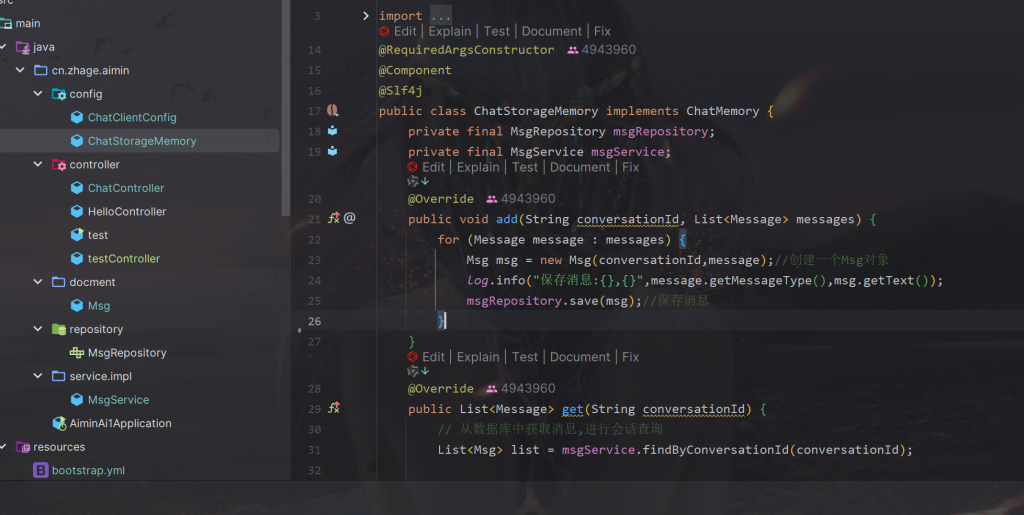
然后我们到ChatClient中,
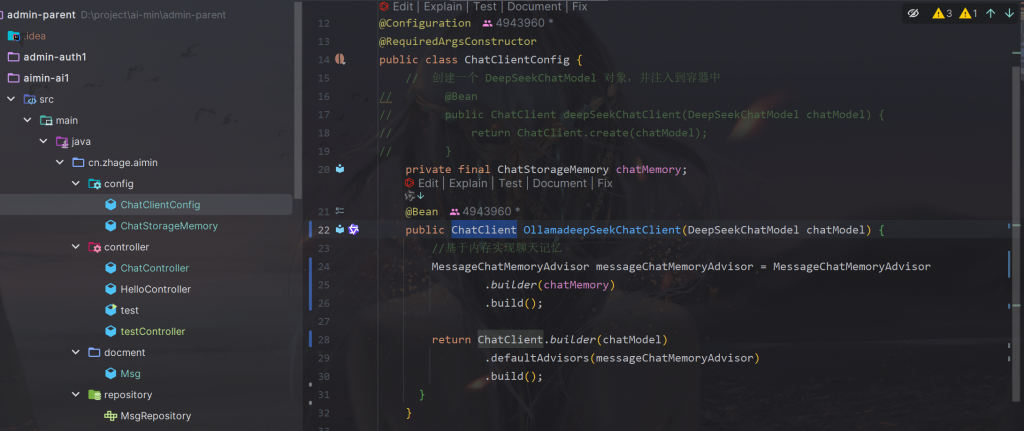
将chatMemory放到ChatClient中就可以实现聊天记忆
COMMON模块:
该模块主要放一些公共的组件,比如数据源啊等等
我们创建一个common模块只保留pom文件,类似aimin-parent,然后我们在此创建子模块,common的父项目依旧是aimin-parent,子模块的父项目是common
因为我们要做全局数据源统一配置,在auth等模块中引入ds依赖,所以我们在auth等模块(需要数据源配置的模块)引入bootstrap依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>然后我们在其配置文件中配置,首先将原来的application.yml改为bootstrap.yml,然后再配置
spring:
config:
import:
- optional:classpath:application.ymlspring.config.import 的作用
1. 配置文件导入机制
- 这是 Spring Boot 2.4+ 引入的新配置导入机制
- 用于在运行时动态导入额外的配置文件
- optional: – 表示这个配置文件是可选的,如果文件不存在不会报错
- classpath: – 表示从 classpath(类路径)中查找文件
- application.yml – 要导入的配置文件名
3. 为什么需要这个配置
在你的项目中:
- 主配置文件是 bootstrap.yml
- 但你可能还有其他配置在 application.yml 中
- 通过这个配置,Spring Boot 会同时加载两个配置文件
4. 配置文件加载顺序
Spring Boot 会按以下顺序加载配置:
- bootstrap.yml (先加载)
- application.yml (后加载,会覆盖前面的配置)
由于common中的ds模块不需要启动,自然没有启动类,这个ds模块被谁注入,谁就可以将ds中的一些bean给配置在自己模块中的ioc容器中,那么怎么才能实现这个功能呢,
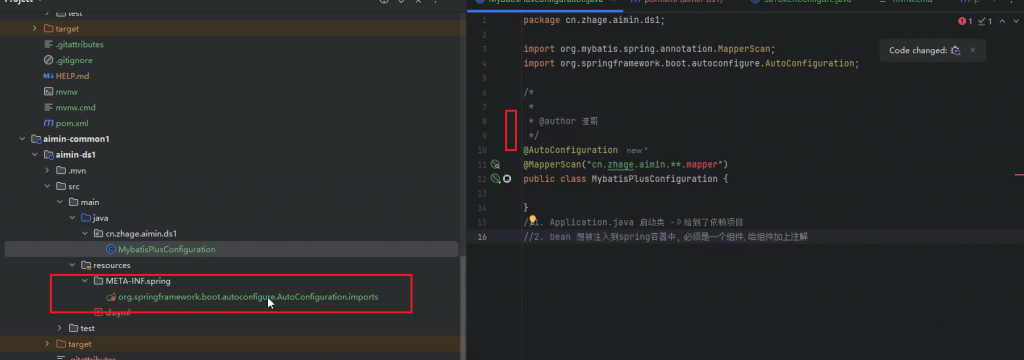

写入到org.springframework.boot.autoconfigure.AutoConfiguration.imports这个文件中jiuok,固定写法
将需要声明的bean在ds中org.springframework.boot.autoconfigure.AutoConfiguration.imports声明出来
MybatisPlusjoinhttps://mybatis-plus-join.github.io/pages/quickstart/quickstart.html
动态代理:

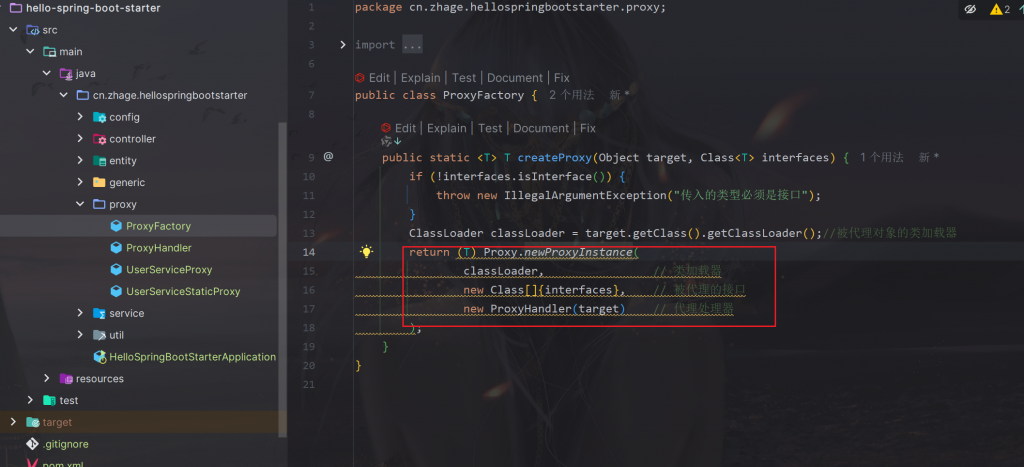
主要是通过Proxy.newProxyInstance来创建代理对象,里面有三个参数,一个是类加载器(固定),一个是
被代理的接口,比如UserService,还有一个就是被代理的类
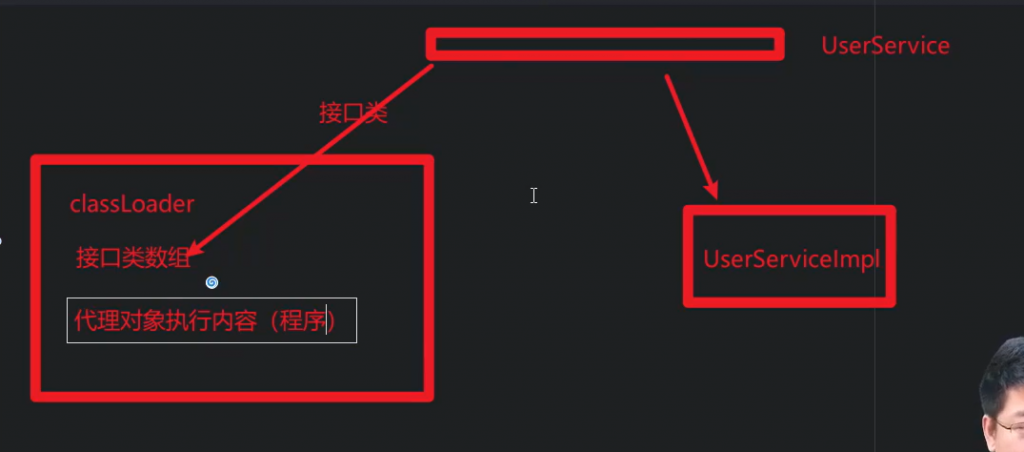
可以看到newProxyInstance有三个参数,
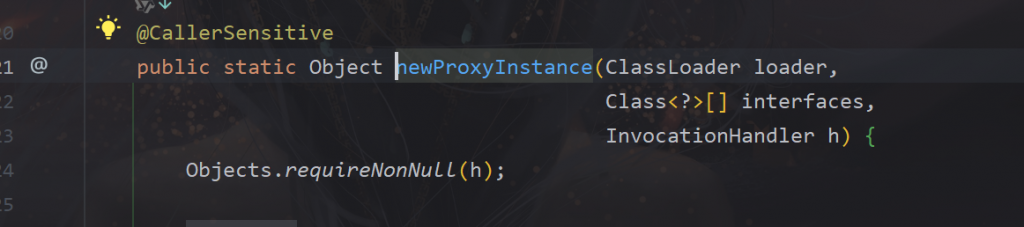
InvocationHandler是个接口,所以需要实现一下
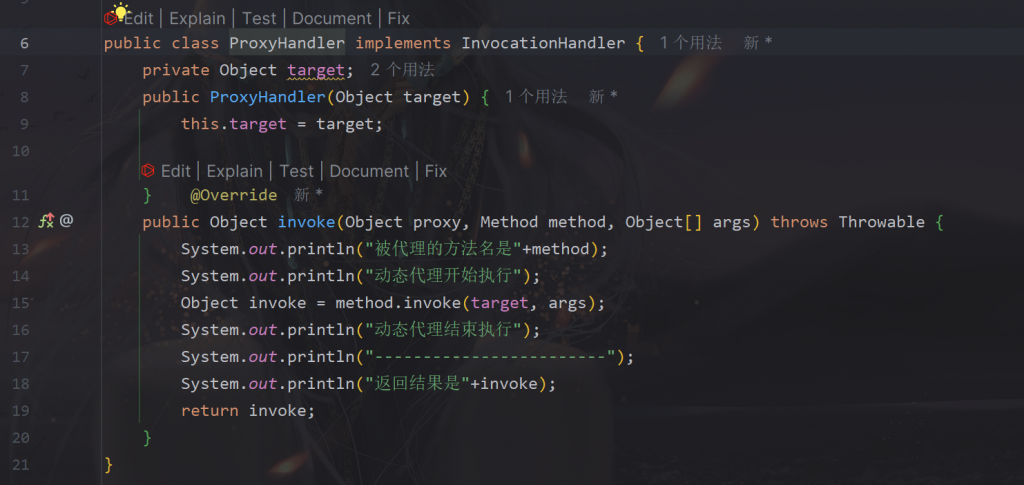
具体实现:只需要实现invoke方法
Satoken-Redis集成方案:
在配置好redis模块信息后,直接在
中添加
<dependency>
<groupId>cn.dev33</groupId>
<artifactId>sa-token-redis-jackson</artifactId>
</dependency>就代表已经将satoken存储方案改为redis


他会默认使用redis里面的所有默认配置
基于gateway:实现网关鉴权
在网关中添加以下依赖:
<!-- Sa-Token 权限认证(Reactor响应式集成), 在线文档:https://sa-token.cc -->
<dependency>
<groupId>cn.dev33</groupId>
<artifactId>sa-token-reactor-spring-boot-starter</artifactId>
<version>1.44.0</version>
</dependency>
<!-- Sa-Token 整合 Redis (使用 jackson 序列化方式) -->
<dependency>
<groupId>cn.dev33</groupId>
<artifactId>sa-token-redis-jackson</artifactId>
<version>1.44.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
这里呢,我们把satoken给清理出来了
我们把SaTokenConfigure配置文件放到satoken starter里面
注意:
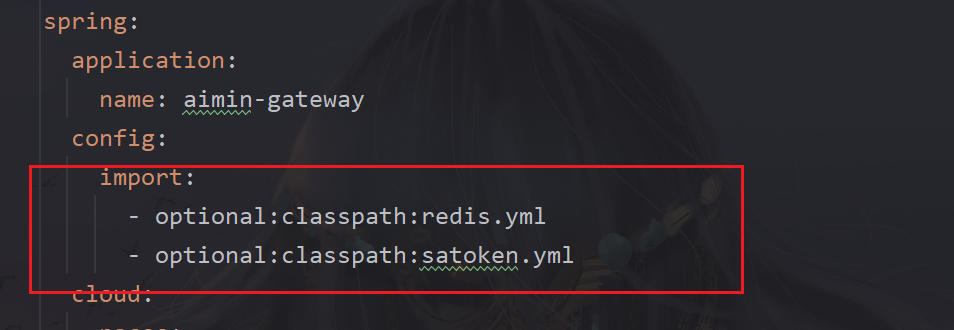
config是和cloud同一级,不用弄错,不然连接不上redis的那个starter
实现多账号登录:

如果tokenName一样,那么管理端就会有风险接口数据
那在管理端存token的时候tokenName改为admin-auth-token就好了
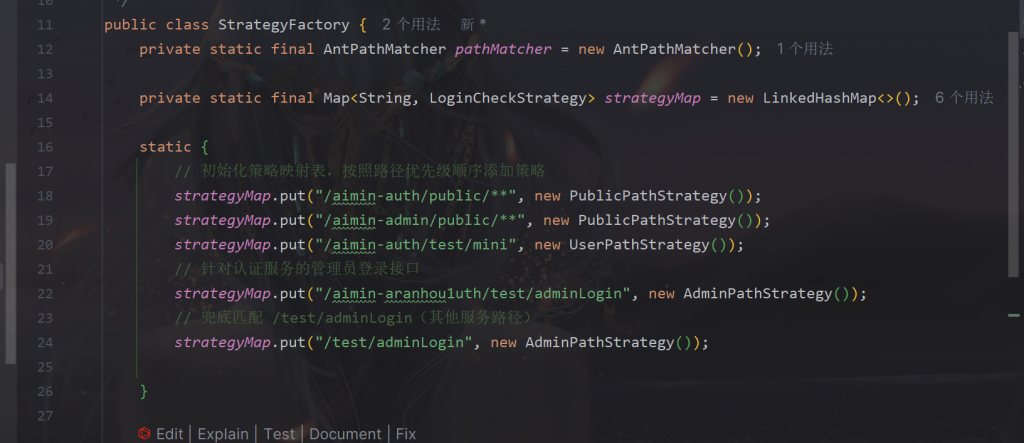
多账号认证登录用到了策略模式
用到了策略模式+简单工厂。
- 策略接口:LoginCheckStrategy
- 具体策略:AdminPathStrategy、PublicPathStrategy、UserPathStrategy
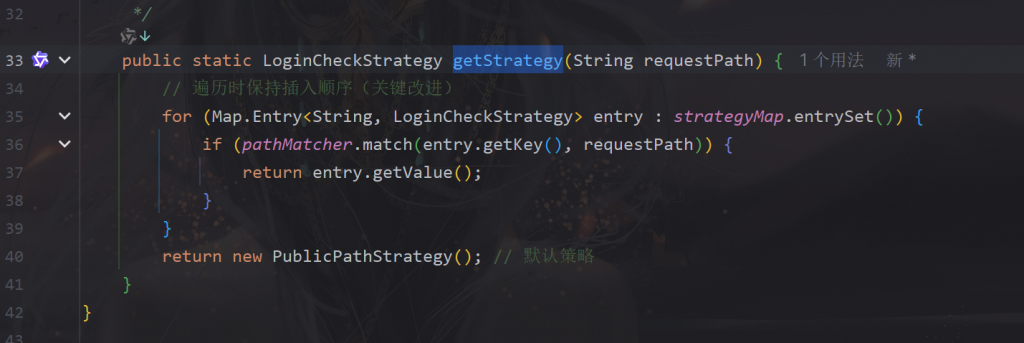
- 策略选择器(简单工厂):StrategyFactory#getStrategy(String) 按路径用 AntPathMatcher 从 LinkedHashMap<String, LoginCheckStrategy> 中挑选策略,未命中返回默认 PublicPathStrategy。
建议优化:
- 保证匹配优先级:已用 LinkedHashMap,高优先级规则放前面即可。
- 将策略改为 Spring Bean(如有依赖注入需求),工厂里从容器获取。
- 支持模式分组:如 /aimin-auth/test/** 统一走 UserPathStrategy,减少单接口配置。
实现截图:
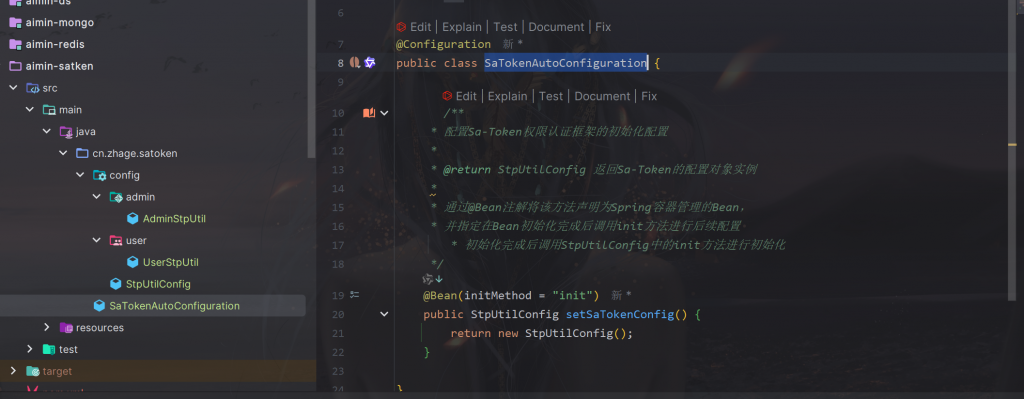
首先我们在satoken模块定义了SaTokenAutoConfiguration,通过 @Configuration + @Bean 把 StpUtilConfig 作为 Spring Bean 放入容器。
初始化钩子
@Bean(initMethod = “init”) 会在 Bean 创建后自动调用 StpUtilConfig#init(),用于完成 Sa-Token 相关的初始化(例如自定义 StpUtil、注册多端登录逻辑、全局拦截器等)。
便于模块复用
放在公共模块 aimin-satken 中,被任意业务模块依赖后即可“开箱即用”,无需在每个业务模块重复配置。
一句话:集中化、自动化地完成 Sa-Token 的初始化与配置注入。
在StpUtilConfig中我们配置了setTokenName,用户端和管理端的具体信息
然后我们在
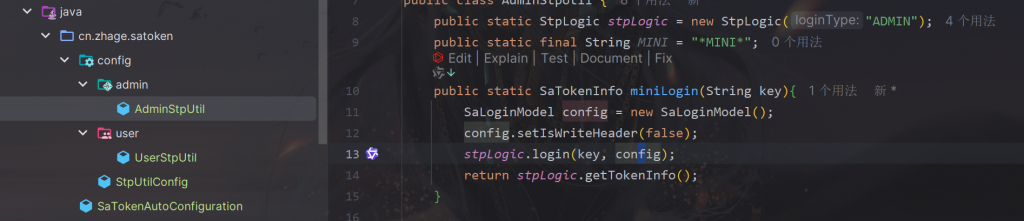
配置了用于校验用户端和管理端的stpLogic,用于校验不同身份的用户
然后我们来到网关,
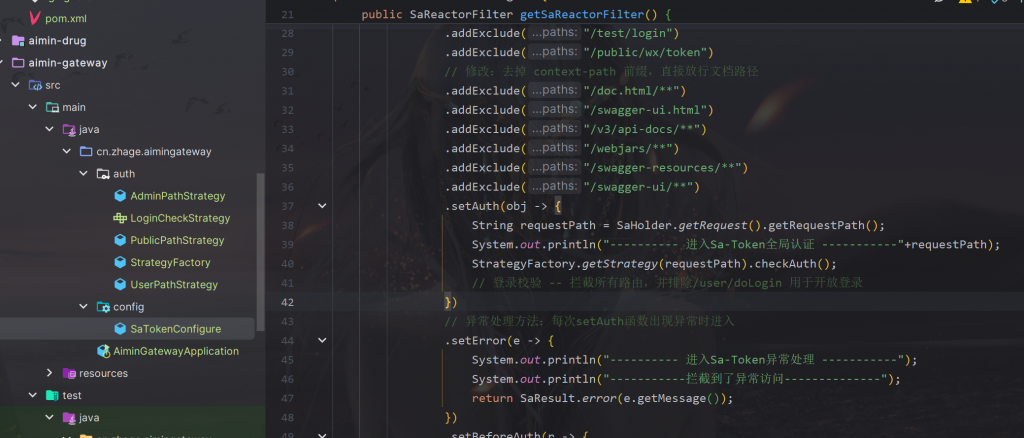
这里我们配置了一个过滤器,通过String requestPath = SaHolder.getRequest().getRequestPath();去匹配不同路径的请求从而让不通的校验器去校验
我们写一个接口

让userPathStrategy等去实现它(多态的实现),
然后我们用StrategyFactory中getStrategy去校验
这里设置好哪种路径请求用哪个校验器
缓存实现:
我们使用的是caffeine,这个caffeine作为一级缓存,

我们设置了它的配置信息过期时间为20s,我们在pom文件中导入redis的依赖以及配置信息
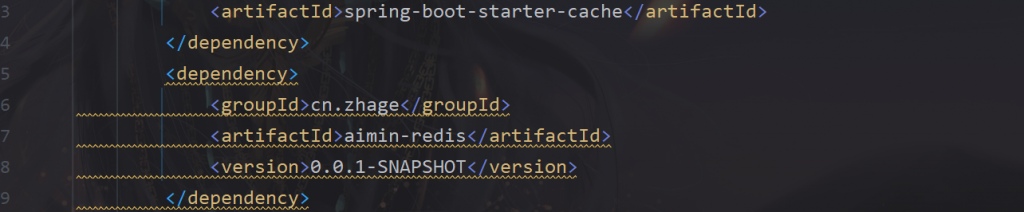
那么他就会默认走二级缓存