
SQL语句分类:

一共四种分别为DDL,DML,DQL,DCL
DDL:数据定义语言
DML:数据操作语言
DQL:查询语言
DCL:数据控制语言
语法总结:
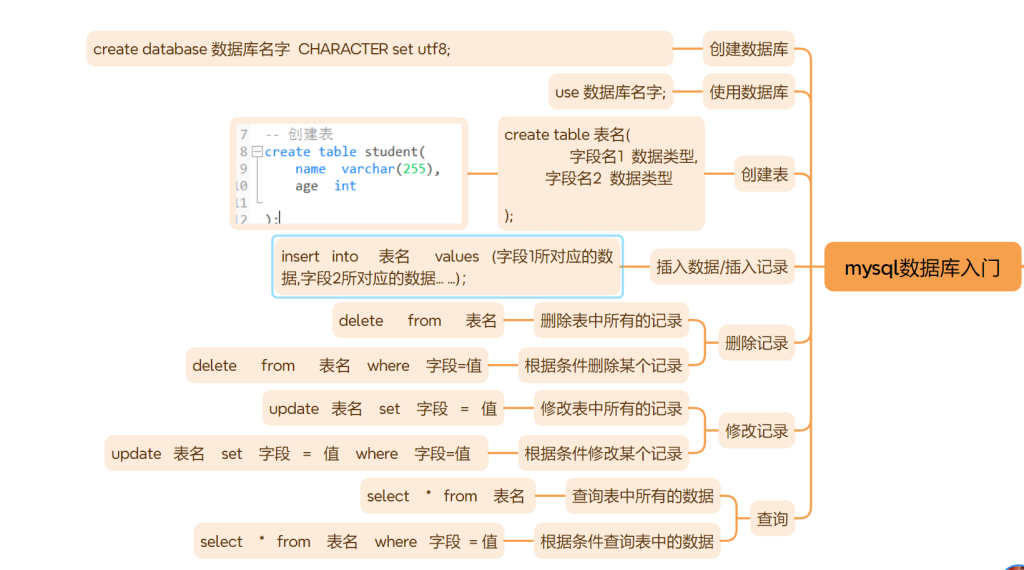
--显示当前数据库
show databases
-- 使用数据库
use xxx;
--创建数据库
create database [if not exists] 数据库名
--查询数据库下表
show tables;
-- 显示表
show table;
-- 创建表
create table xxx;
-- 删除表
drop table xxx;
--查看表结构
describe xxx; 或 desc xxx;
--修改表名
alter table <表名> rename <表名>;
--修改表字段信息
alter table 表名 change 字段名 修改后的列名和属性;
--增加表字段信息
alter table 表名 add 字段名及属性
--删除一个表字段
alter table 表名 drop 字段名;
--插入数据
insert into 表名 value(根据表结构插入数据内容 );
--插入数据,指定属性
insert into 表名 (列名) value(根据表结构插入数据内容 );
--修改数据
update 表 set 字段1=value1, 字段2=value2... where 条件
--删除数据
delete from 表 where 条件
--查看索引
show index from 表名;
--创建索引 对于非主键、非唯一约束、非外键的字段,可以创建普通索引
create index 索引名 on 表名(字段名);
--删除索引
drop index 索引名 on 表名;
--事务
那就让这里两个操作要么同时成功,要么同时失败。这就是事务的逻辑。
(1)开启事务:start transaction;
(2)中间执行多条SQL语句
(3)回滚或提交:rollback/commit;
-- 全列查询
select * from 表
-- 指定列查询
select 字段1,字段2... from 表
-- 查询表达式字段
select 字段1+100,字段2+字段3 from 表
-- 别名
select 字段1 别名1, 字段2 别名2 from 表
-- 去重DISTINCT
select distinct 字段 from 表
-- 排序ORDER BY
select * from 表 order by 排序字段
-- 条件查询where:
(1)比较运算符 (2)BETWEEN ... AND ... (3)IN (4)IS NULL (5)LIKE (6)AND (7)OR(8)NOT
select * from 表 where 条件
>, >=, <, <=,=,<=>(等于),!=, <>
between a and b,IS NULL,IS NOT NULL
IN (option, ...) 如果是 option 中的任意一个,返回 TRUE(1)
LIKE 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符
逻辑运算符:and,or,not
--分页查询limit--从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
select ... from 表名[where...][order by..] limit s offset n;
--聚合函数
COUNT([DISTINCT] expr)(计数),SUM([DISTINCT] expr),AVG([DISTINCT] expr),MAX([DISTINCT] expr),MIN([DISTINCT] expr)
select role,max(salary),min(salary),avg(salary) from emp group by role;
--group by 分组查询 having 条件过滤
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING
显示平均工资低于1500的角色和它的平均工资
select role,max(salary),min(salary),avg(salary) from emp group by role
having avg(salary)<1500;
--联合查询
--内连接
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
--自连接,自连接是指在同一张表连接自身进行查询。
select 字段 from 表1 别名1 join 表1 别名2 on 连接条件 join 表2 别名1 on 条件 join 表12别名2 .......and 其他条件;
--子查询
-- 单行子查询
select ... from 表1 where 字段1 = (select ... from ...);
--多行子查询
-- [NOT] IN
select ... from 表1 where 字段1 in (select ... from ...);
-- [NOT] EXISTS
select ... from 表1 where exists (select ... from ... where 条件);
-- 临时表:form子句中的子查询
select ... from 表1, (select ... from ...) as tmp where 条件
在from子句中使用子查询:子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。
----在from子句中使用子查询:子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。
-- UNION:去除重复数据(操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。)
select ... from ... where 条件
union
select ... from ... where 条件
-- UNION ALL:不去重(该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行)
select ... from ... where 条件
union all
select ... from ... where 条件
使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致
--数据库约束
NOT NULL - 指示某列不能为空
UNIQUE - 保证某列的每行必须有唯一,不重复的。
DEFAULT - 规定没有给列赋值时的默认值。
PRIMARY KEY - 主键约束,与 NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
FOREIGN KEY - 外键约束,保证一个表中的数据匹配另一个表中的值的参照完整性。
CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。