什么是索引?
官方定义:索引是一种帮助mysql提高查询的数据结构
索引缺点:索引需要耗费数据资源,索引需要占用磁盘空间,当对表的数据进行增删改的时候,速度会受到影响。(删除修改增加/一个元素可能会对底层数据结构进行重排序)
索引分类:
主键索引:设定为主键后数据会自动建立索引,innodb为聚簇索引,主键索引列值不能为空
单列索引:即一个索引包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值必须唯一,但允许有空值,只能有一个
复合索引:即一个索引包含多个列
主键索引:主键索引在建表的时候自动创建,在主流数据库当你为字段定义 primary key 时,都会自动创建对应的主键索引
- 如果表中存在一个
NOT NULL且UNIQUE的字段,InnoDB 会使用该字段作为聚簇索引。
自动生成隐藏主键列(ROW_ID):
- 如果没有主键,也没有合适的唯一索引,InnoDB 会自动生成一个隐藏列
ROW_ID,作为聚簇索引。
create table t_user(
id varchar(32) primary key ,
name varchar(32)
);
查看索引:
show index from t_user ;

普通索引创建有两种方式:
一种是建表的时候,另一种是建表之后进行创建
建表后这样创建:
create index index_name on t_user(name);

在show index from t_user 现在就有两个索引
还可以这样:alter table t_user add column age int, add index index_age(age);
建表时创建索引:
create table t_user( id varchar(20) primary key,name varchar(20) ,ley (name)); //这里就为name字段自动创建一个索引,索引名称不可指定
唯一索引:
建表的时候创建
create table t_user(id varchar(32) primary key ,name varchar(32),unique(name) )
建表后创建唯一索引:
create index unique nameindex on t_user(name);
删除索引: drop index nameindex on t_user
复合索引:
复合索引中的字段顺序绝对不是随便填的,它对查询性能和索引是否能被有效使用有非常关键的影响。


复合索引:
建表时创建:
create table t_user(id varchar(20) peimary key ,name varchar(32) ,age int, key(name ,age));
建表后创建:create index nameageindex on t_user(name,age);
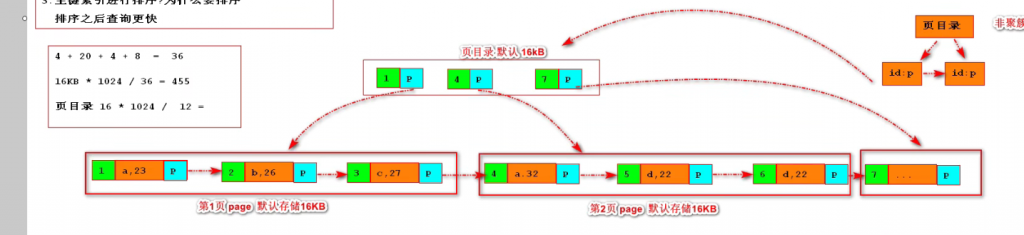
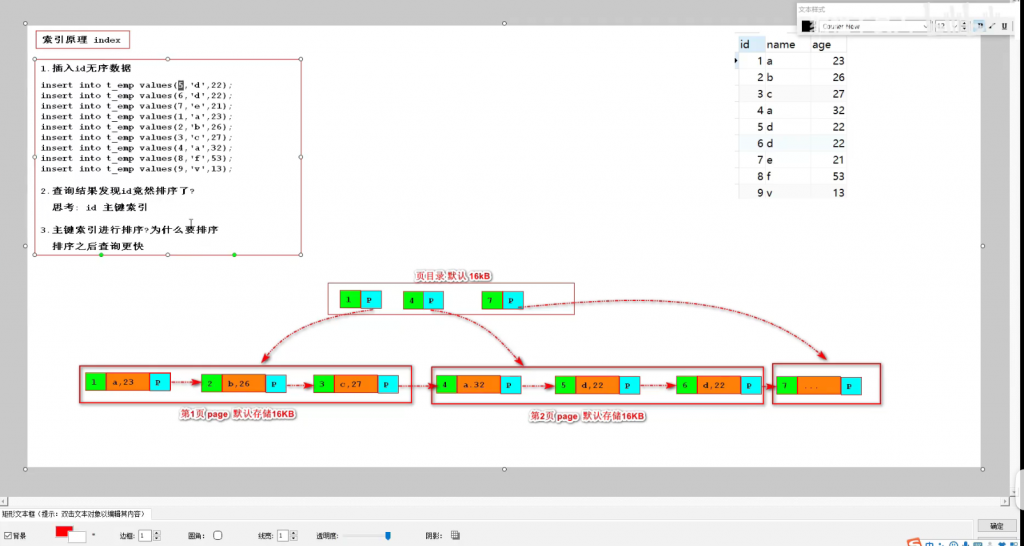
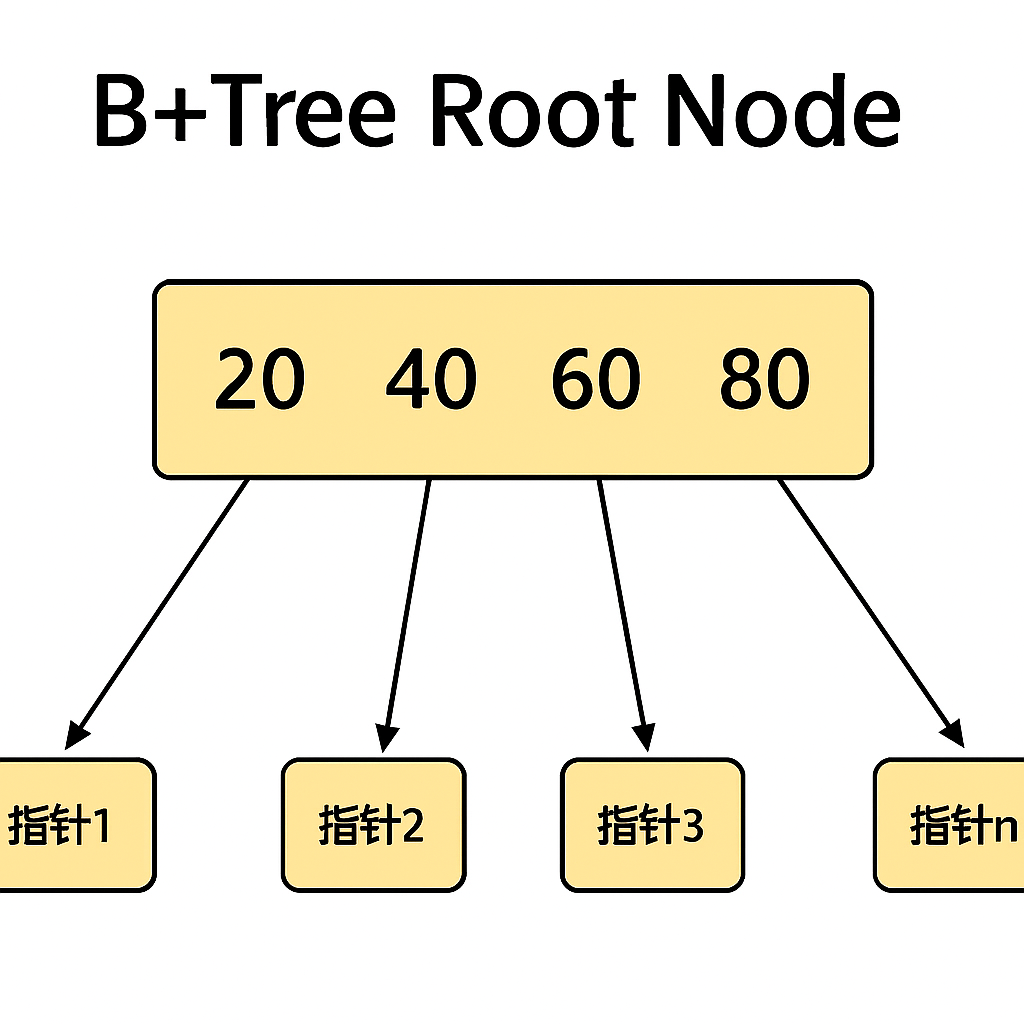
索引底层原理:
这个表在创建的时候定义主键是primary key ,默认有一个主键索引
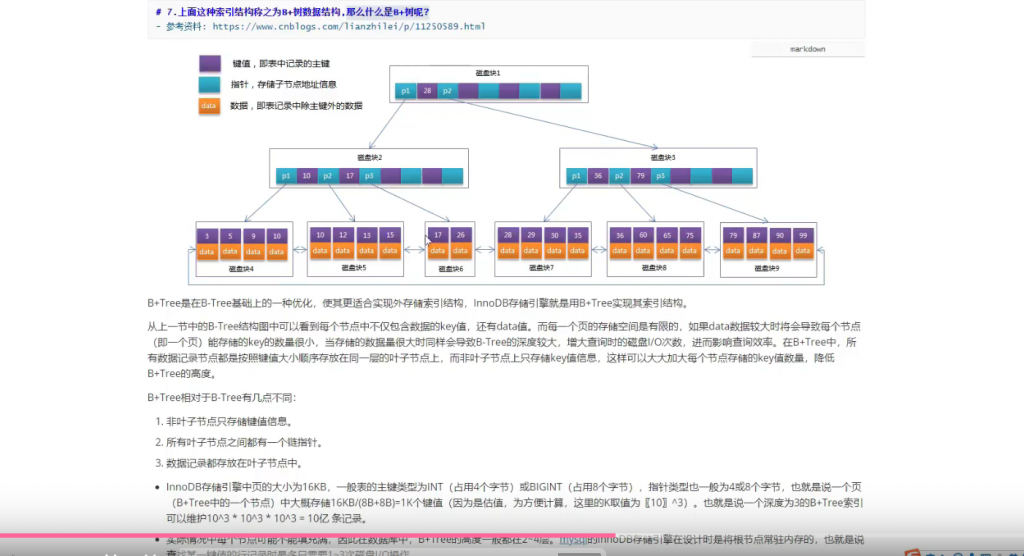
B树和B+树的主要区别在于数据存储位置和查询效率:B树的所有节点都存储数据,而B+树只有叶子节点存储数据,非叶子节点仅用于索引。
索引的数据结构是一个B+树,我们在放入数据的时候他会基于数据进行一个排序,之后会将数据以链表指针的形式链接起来,
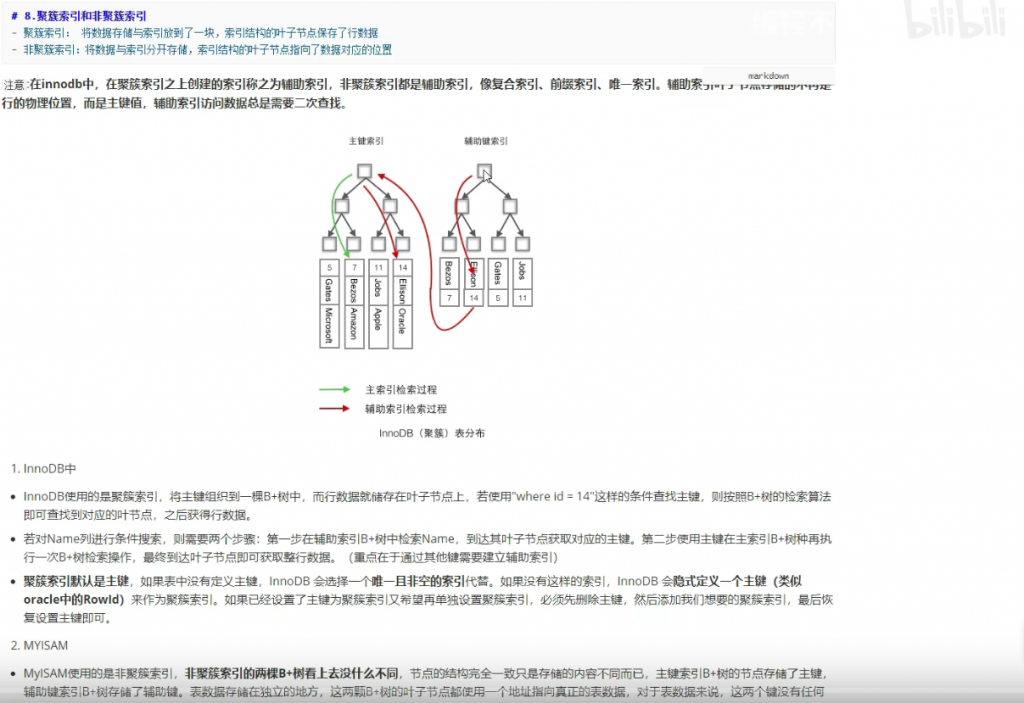
聚簇索引和非聚簇索引:
聚簇索引:将数据存储和索引放到了一块,索引结构的叶子节点保存了行数据
非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置!


非聚簇索引优势: