第一篇。redis复习
reids使用场景:

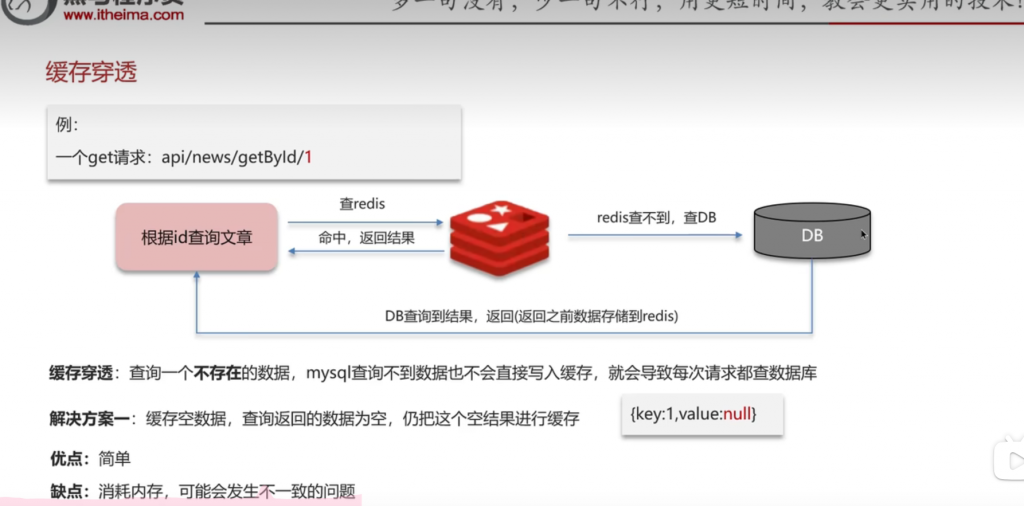
一:缓存穿透
方法一:缓存空数据
解决方法二:布隆过滤器
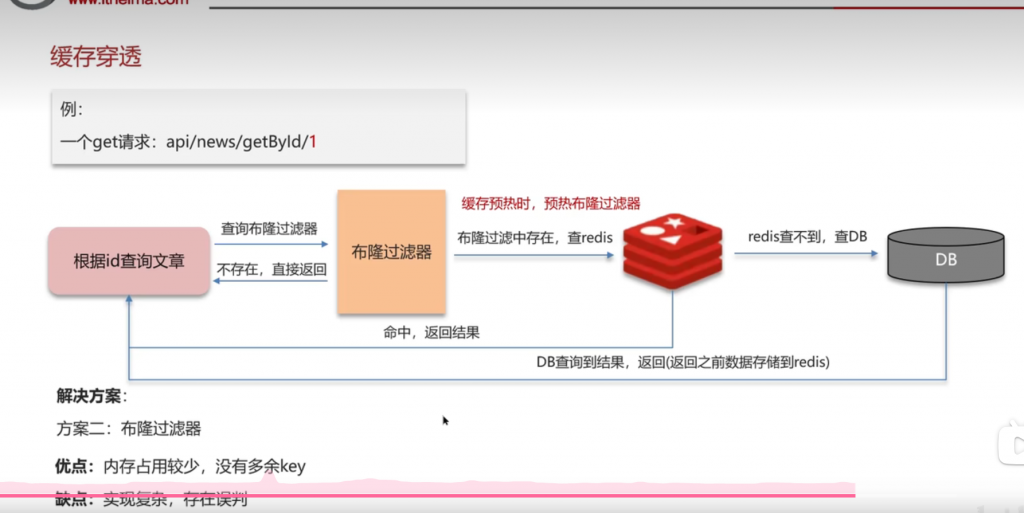
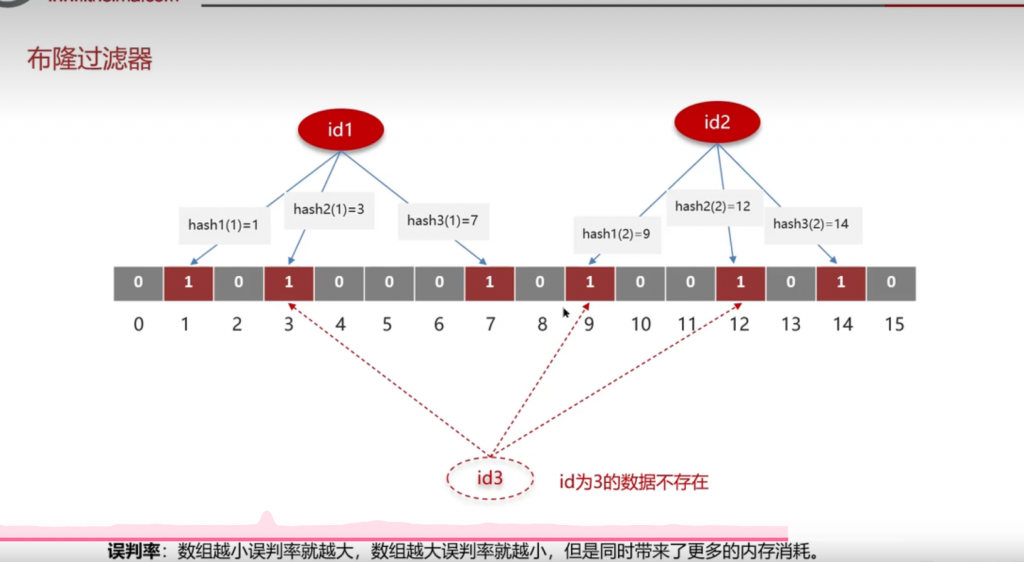
布隆过滤器:

每次请求的数据会计算其hash值,如果不存在,那么在布隆过滤器中的值为1,否则为0,在redis缓存预热的时候,也要把布隆过滤器给预热
布隆过滤器可能产生误判
布隆过滤器本质是一个二进制数组(bit array,每个元素只有 0/1 两种状态) + 多个独立的哈希函数,它不存储 “值本身”,只存储 “值存在的痕迹”
二、关键逻辑:布隆过滤器与 MySQL 的 “数据同步关系”
布隆过滤器的 “零假阴性”(判断不存在则一定不存在),需要一个前提:所有 MySQL 中 “存在的值”,都已经提前写入了布隆过滤器。
在实际业务中,这个前提是通过 “数据写入流程的强绑定” 实现的:
- 当我们向 MySQL 插入一条新数据(比如新增
user_id=789)时,会同步执行 “将该值写入布隆过滤器” 的操作(即完成上述 “哈希映射 + 位设为 1” 的步骤); - 当 MySQL 中删除一条数据时(虽然布隆过滤器不支持直接删,但可通过 “定期重建布隆过滤器” 确保一致性:用 MySQL 现有所有数据重新构建一个新的布隆过滤器,替换旧的)。
二:缓存击穿
解决方案:1:互斥锁 2 :逻辑过期
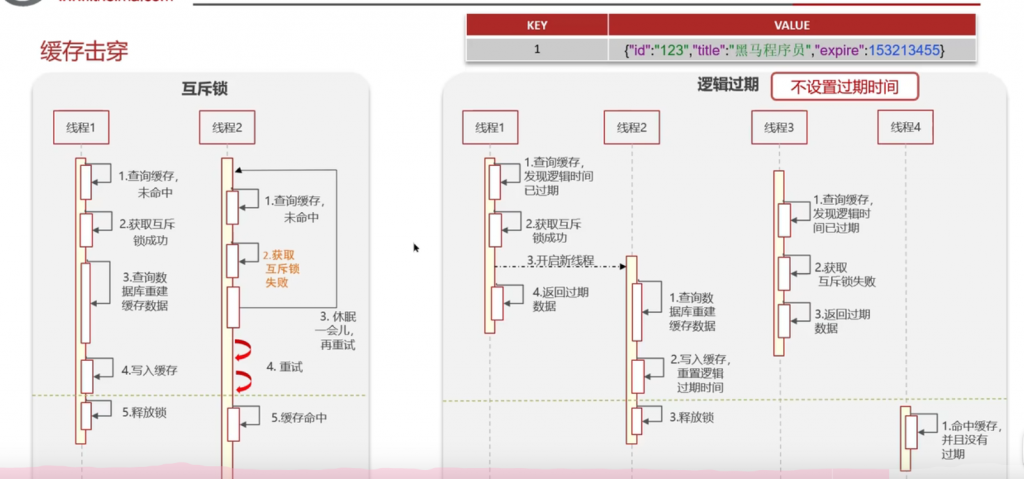
互斥锁可以保证数据强一直性,缺点就是性能差
逻辑过期:高可用,性能优
根据具体业务场景进行选择
总结:

三:缓存雪崩
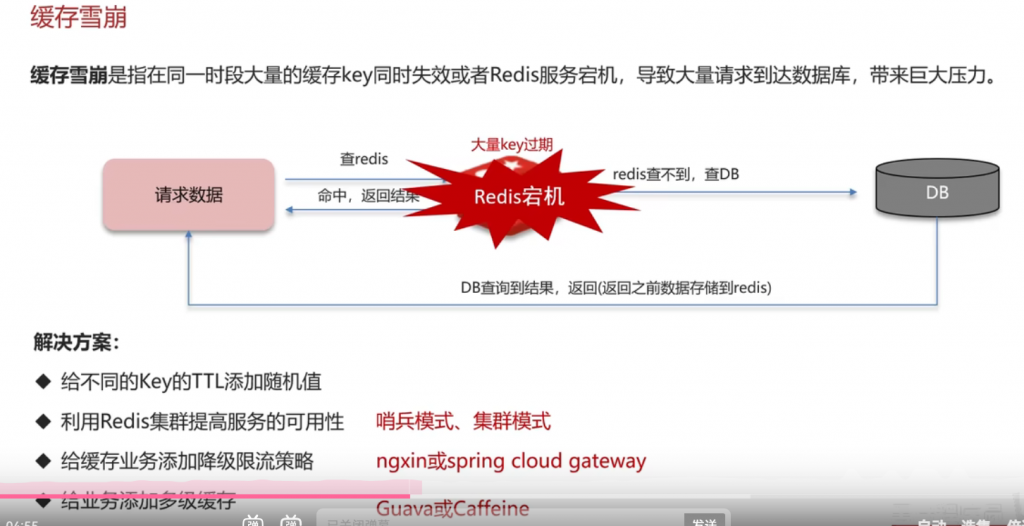
总结:


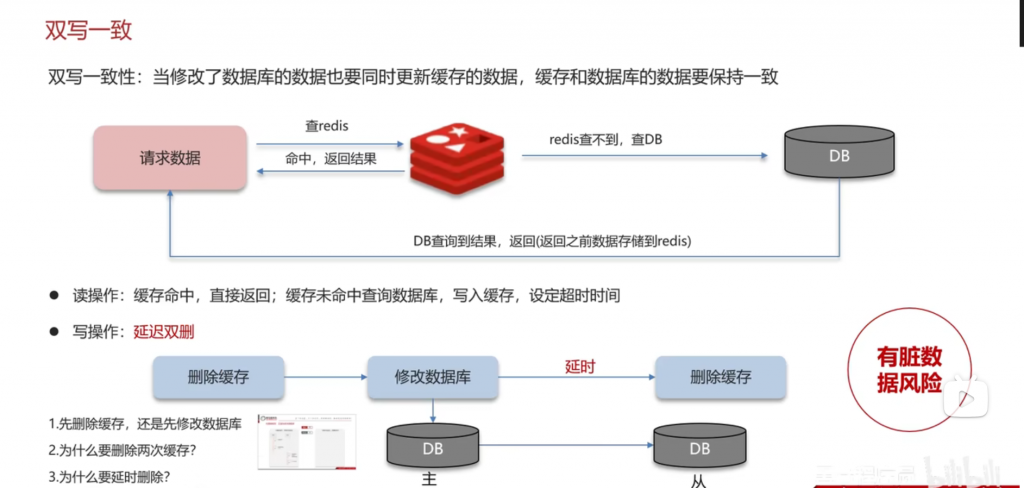
四 双写一致:
问:redis作为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
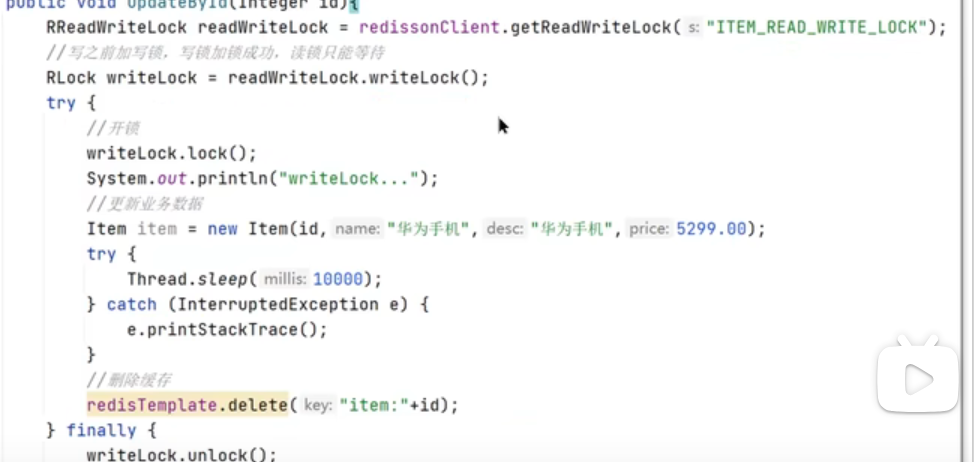
第一种情况:要求强一致性
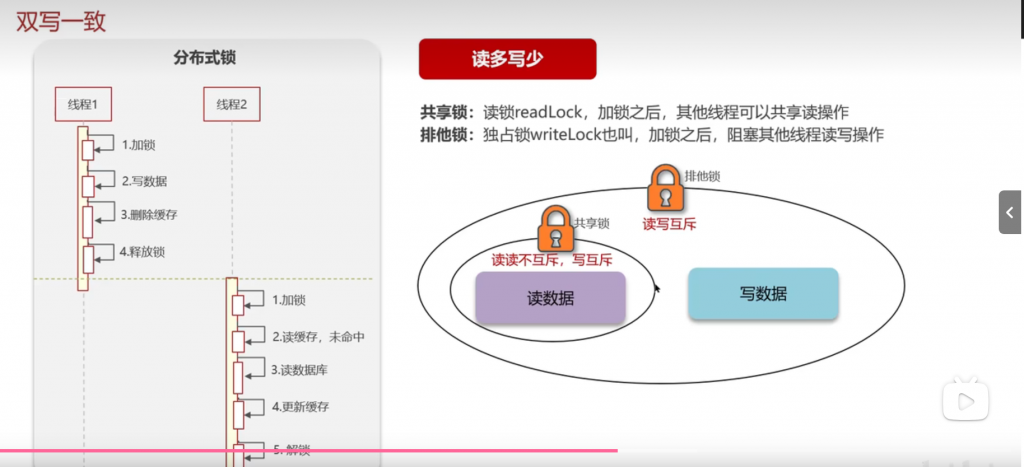
读写锁:
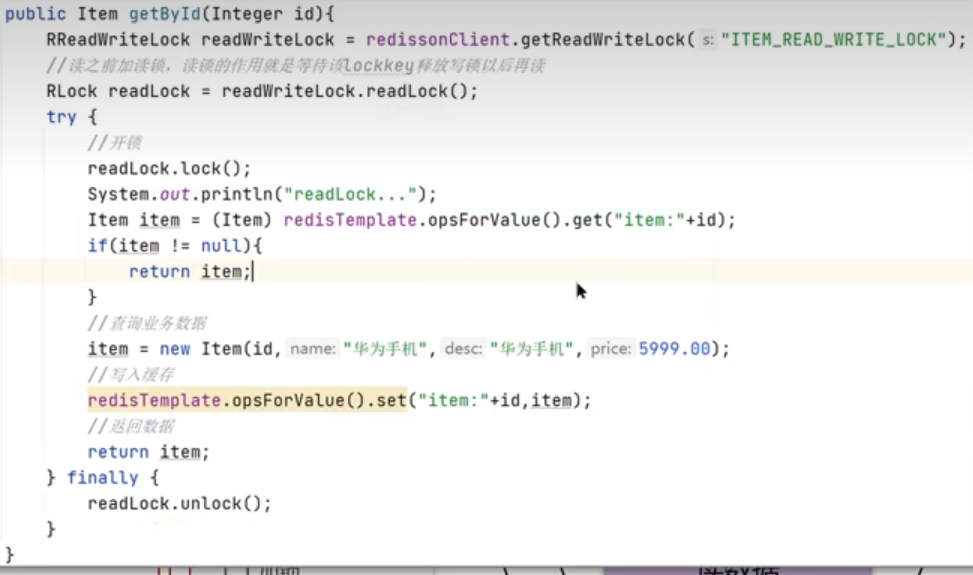
排他锁:
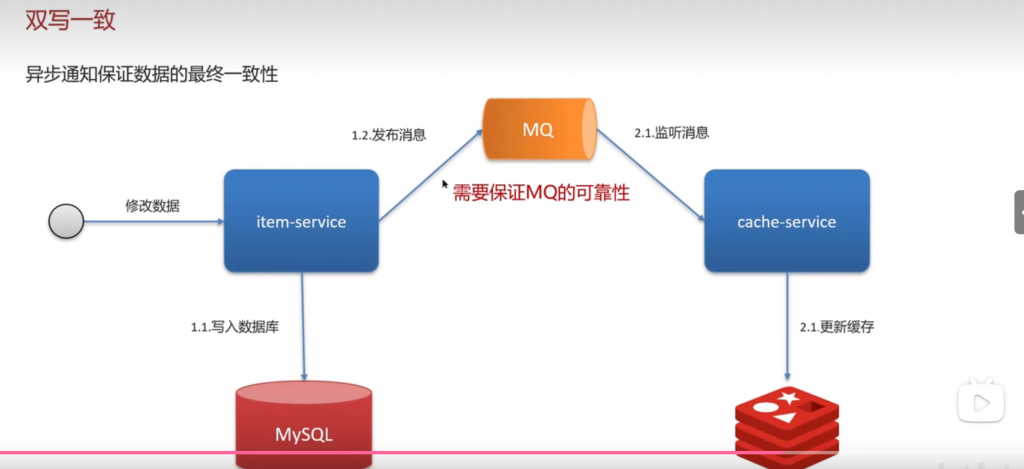
第二种情况(可以接收短暂不一致):
方案一:
异步通知保证数据的最终一致性:基于mq
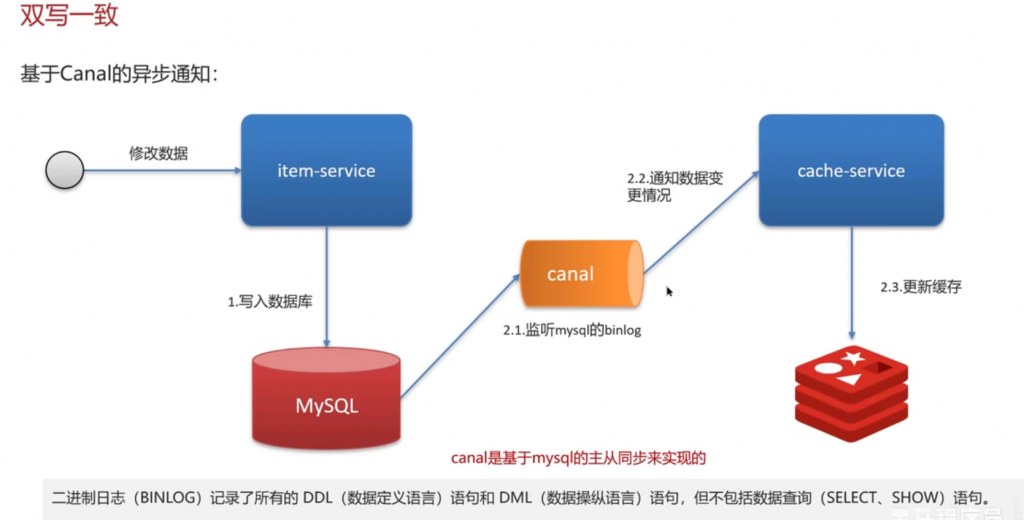
方案二:
基于canal的异步通知:
总结:



五:redis持久化
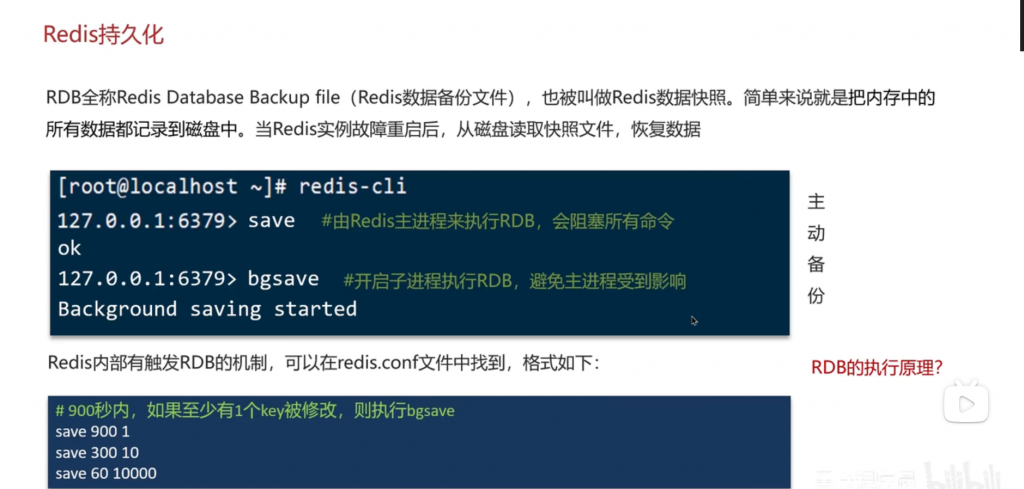
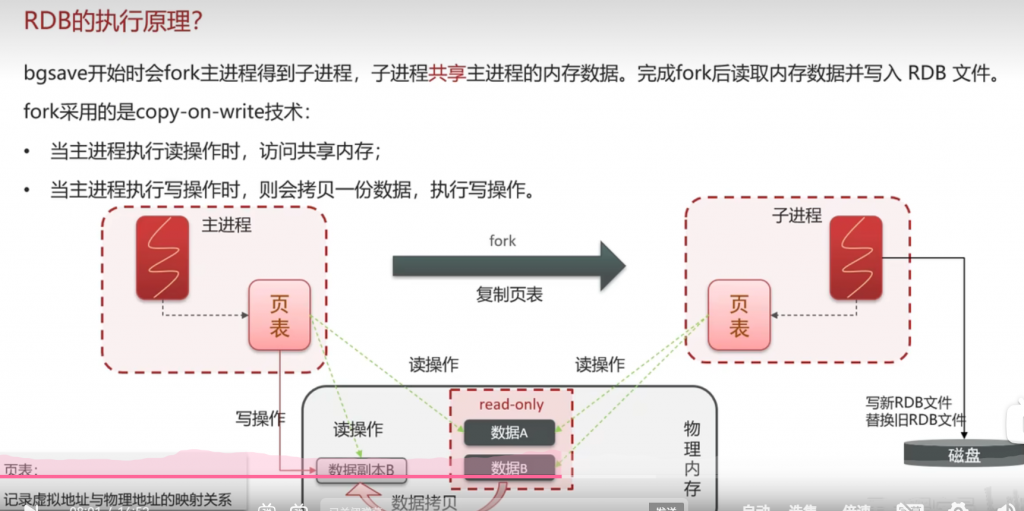
方式一:RDB
方式二:AOF
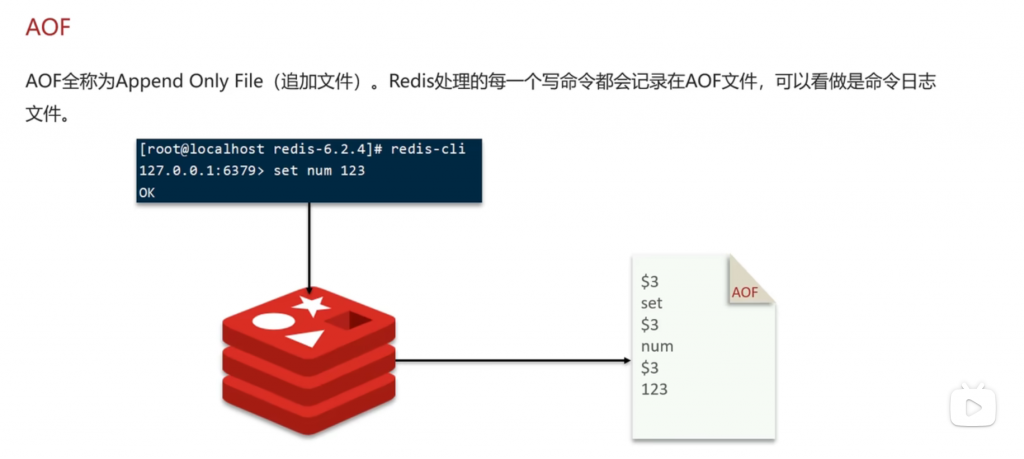


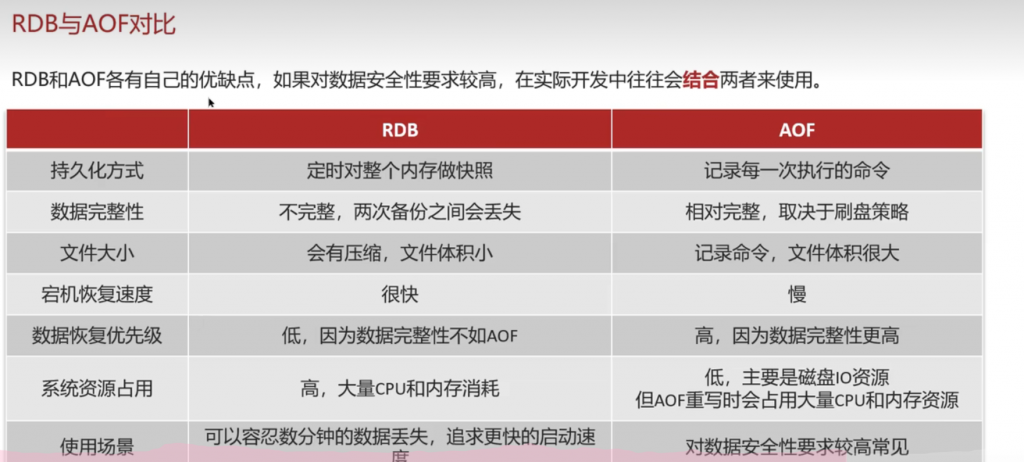

RDB和aof在redis数据失效重启后如果查询到有rdb或者aof文件会自动恢复,无需人工干预
AOF 和 RDB 文件不存在内存中,而是持久化存储在磁盘中的文件 —— 这正是 Redis “持久化” 的核心意义:将内存中易失的数据(断电 / 重启即丢失)保存到磁盘,避免数据因服务中断而丢失。
六:数据过期策略:
问:假如redis的key过期后,会立即删除吗

有两种解决方案,第一种 惰性删除 第二种 立即删除
惰性删除:

定期删除:


总结:


七:数据淘汰策略:
问:假如缓存过多,内存是有限的,内存被占满了怎么办?
其实就是想问redis的数据淘汰策略是什么




问题八:分布式锁
抢卷场景:
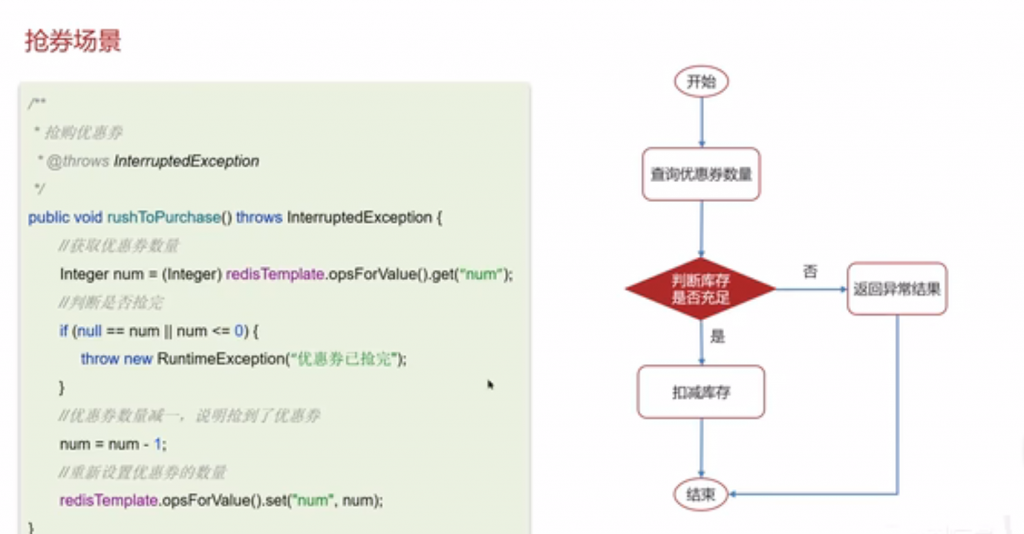
也就是超卖现象,由于线程是交替执行,如果第一个还剩一个,在第一个线程扣减库存之前,第二个线程又查询库存为一,这样两个线程就会扣减两次,最终库存为-1
第一种方法加锁:synchronized
如果是单体项目没问题,如果是集群模式,就不行了
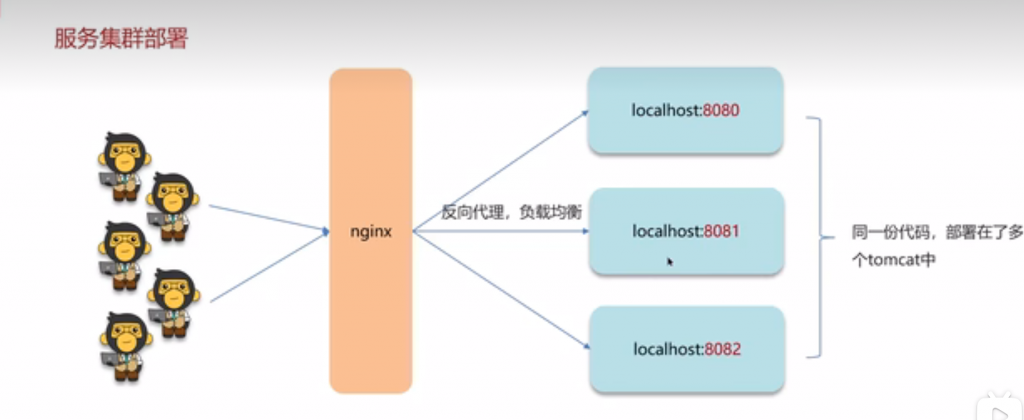
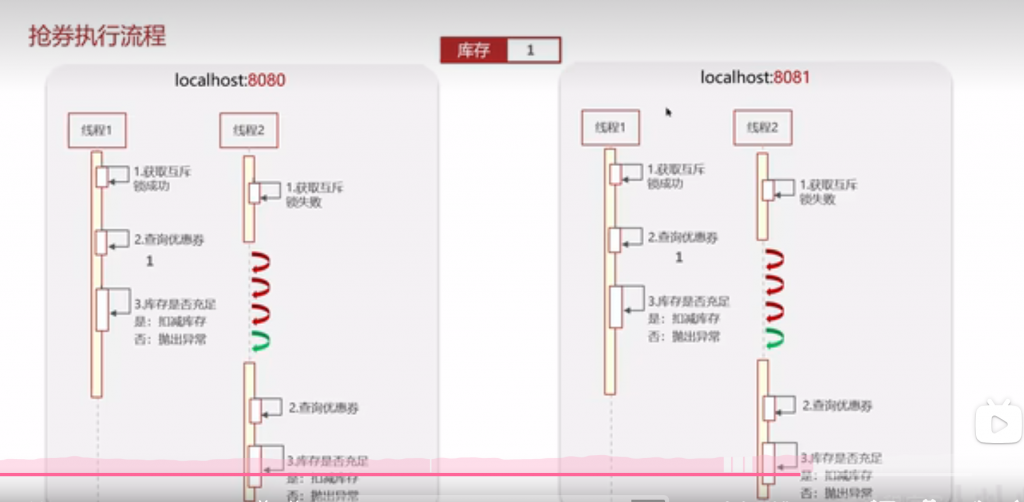
synchronized属于jvm,每个服务器都有各自的jvm
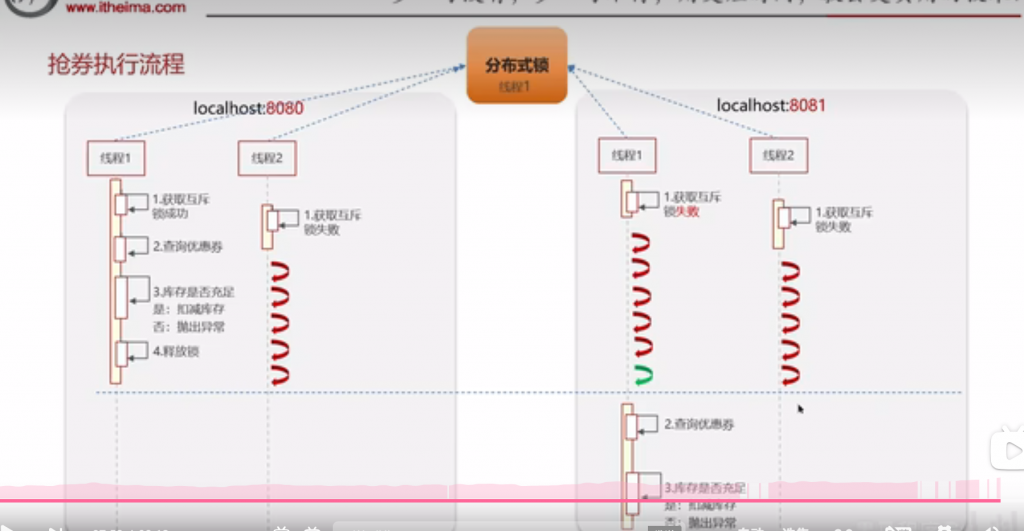
这就是分布式锁
redisson其实已经封装好了现成的分布式锁解决方案:
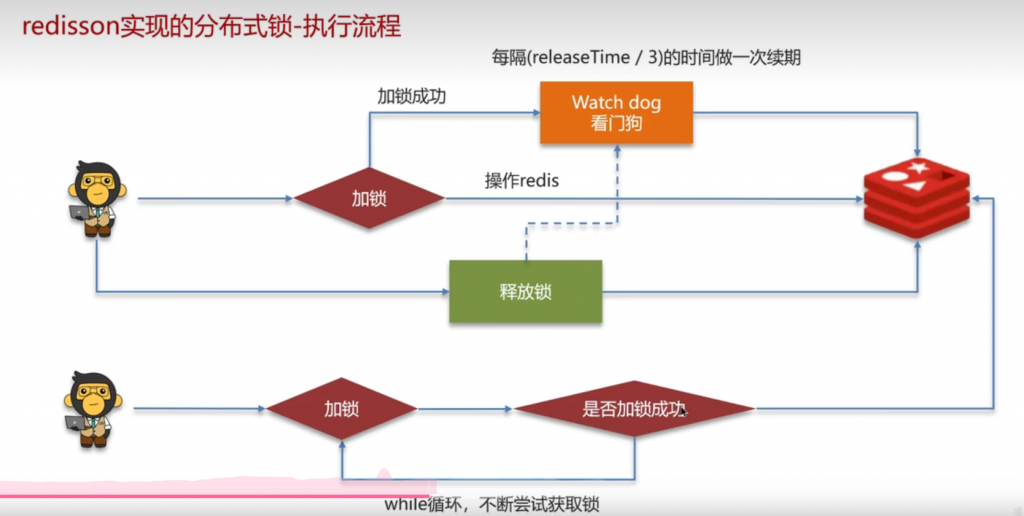
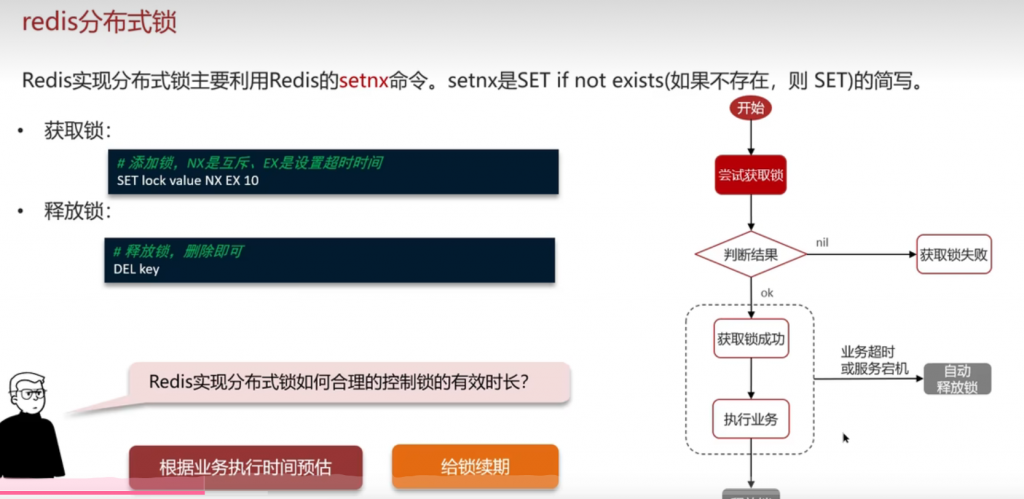
假如锁的释放时间是30秒,如果业务还没完成,那么看门狗就会以10秒的时间进行续期
如果另一个线程未抢到锁,那么就会触发redisson的重试机制,到一定次数可以停止
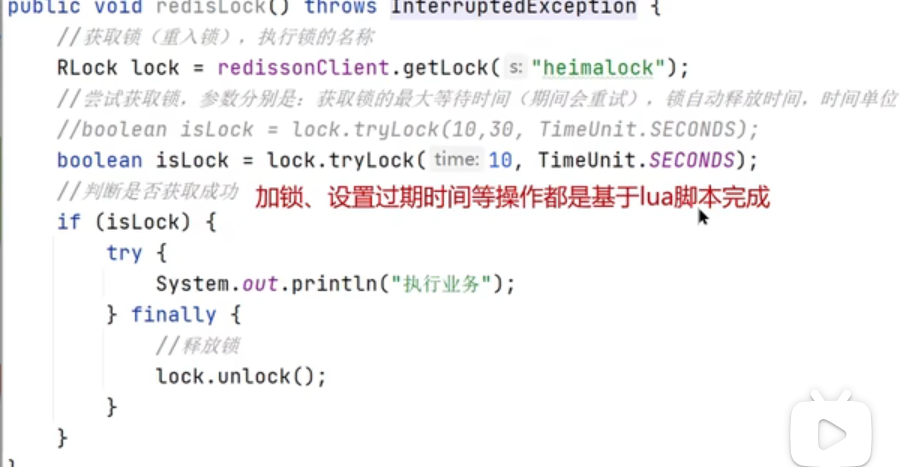
如果填了锁的释放时间,那么redisson就会取消看门狗,不会给你续期,否则会续期
redisson实现的分布式锁可重入

如果是第一个锁那么value就是1,再加一个锁就会是2,释放锁后减一,释放锁
redisson主从一致性:如果主节点(用来写操作),从节点(用来读操作),如果主节点宕机后,那么就会选择一个从节点当做主节点

解决方法:RedLock(红锁)
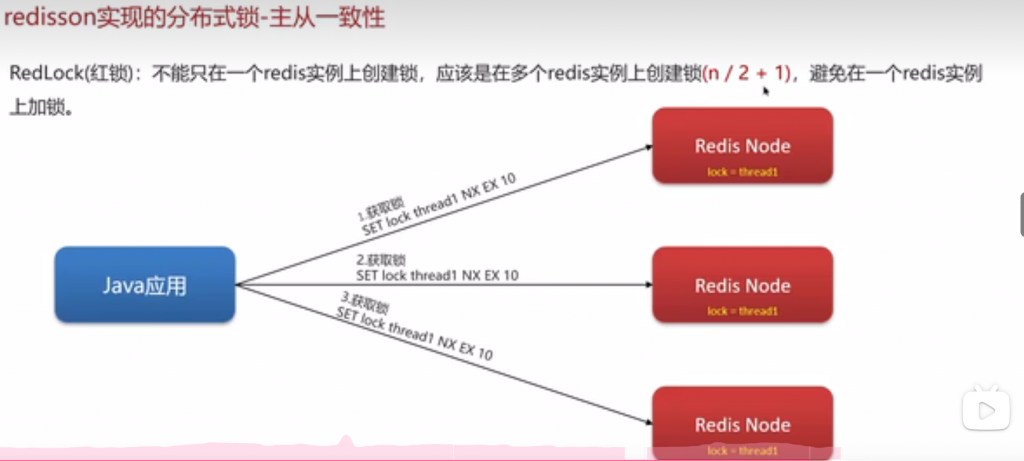
红锁缺点:


红锁
要理解 红锁(Redlock),首先需明确其核心定位:它是 Redis 官方提出的一种分布式锁实现方案,用于解决单机 Redis 锁在 “主从架构 / 集群环境下的可靠性问题”—— 本质是通过多节点冗余,规避单节点故障导致的锁失效风险,确保分布式场景下锁的 “安全性” 与 “可用性”。
一、红锁(Redlock)的诞生背景:解决单机 Redis 锁的致命缺陷
在了解红锁前,需先明确其要解决的核心问题:单机 Redis 锁在主从架构下的 “锁丢失” 风险。
常规的单机 Redis 锁(如用 SET key value NX EX 命令实现)逻辑是:客户端向 Redis 节点发送 “互斥指令”,成功则获取锁,失败则等待 / 放弃。但在 Redis 主从架构中,存在一个致命问题:
- Redis 主从复制是异步的:主节点(Master)处理完锁请求(如
SET lock 1 NX EX 10)后,会直接返回 “锁成功”,但数据同步到从节点(Slave)需要时间。 - 若主节点在同步锁数据到从节点前突然宕机,哨兵 / 集群会将从节点提升为新主节点。此时新主节点中没有之前的锁记录,其他客户端会误以为 “锁已释放”,重新获取到锁 —— 导致 “一把锁被两个客户端同时持有”,破坏锁的 “互斥性”,引发业务数据冲突(如重复下单、并发修改同一数据)。
红锁的设计目标,就是通过多独立 Redis 节点的冗余,彻底解决这种 “单节点故障导致的锁丢失” 问题。
二、红锁(Redlock)的核心原理:“多节点投票,少数服从多数”
红锁的核心逻辑基于 “分布式系统的冗余容错思想”,具体实现需满足两个前提:
- 部署 N 个独立的 Redis 节点(通常 N=5,奇数,避免投票平局):这些节点之间无主从关系,不进行数据复制,完全独立运行(可单机、可容器,甚至跨机房)。
- 客户端实现红锁逻辑时,需通过 “多节点请求 + 投票” 的方式获取锁,而非仅请求单个节点。
红锁的完整执行流程(以 N=5 为例)
红锁的获取与释放过程严格遵循 “少数服从多数” 原则,具体步骤如下:
1. 锁的获取阶段(核心:满足 “多数节点成功”)
客户端要获取红锁,需依次执行以下操作:
- 步骤 1:生成唯一标识(UUID)
客户端生成一个全局唯一的 Value(如 UUID + 线程 ID),用于后续区分 “自己的锁” 和 “其他客户端的锁”,避免误释放他人的锁。 - 步骤 2:设置超时时间(TTL)
定义一个 “锁获取超时时间”(如 50ms),确保客户端向单个 Redis 节点请求锁时,不会因节点故障导致长时间阻塞(超过该时间则放弃该节点,视为请求失败)。 - 步骤 3:向所有 N 个节点发起锁请求
客户端同时(或串行但快速)向 5 个独立 Redis 节点发送 “获取锁” 的指令,指令格式与单机锁一致:SET lock_key 唯一UUID NX EX 锁有效期(NX表示 “不存在则创建”,EX表示 “设置过期时间”,如 10 秒,避免锁永久占用)。
注意:每个节点的请求都需独立计时,超过 “锁获取超时时间”(如 50ms)则视为该节点请求失败。 - 步骤 4:判断是否获取锁成功
客户端统计 “请求成功的节点数量”,若满足两个条件,则认为红锁获取成功:
① 成功的节点数量 ≥(N/2) + 1(即多数节点,N=5 时需 ≥3);
② 所有成功节点的总耗时 ≤ 锁有效期的 1/3(避免因耗时过长,导致部分节点的锁已过期)。
若不满足,则立即进入 “锁释放阶段”(释放所有已成功的节点的锁),避免残留无效锁。
2. 锁的持有阶段(核心:续期避免锁过期)
获取锁成功后,客户端需注意:
- 锁的 “实际有效时间” = 锁有效期 – 锁获取总耗时(如锁有效期 10 秒,获取耗时 2 秒,则实际有效时间为 8 秒)。
- 若客户端的业务逻辑执行时间可能超过 “实际有效时间”,需在锁过期前向 “所有成功的节点” 发起 “锁续期” 请求(如 Redisson 中的
renewExpiration机制),避免锁提前过期被其他客户端抢占。
3. 锁的释放阶段(核心:清理所有节点的锁)
无论业务逻辑执行成功或失败,客户端都必须释放锁,避免死锁:
- 客户端向所有 5 个节点发送 “释放锁” 的指令(即使某个节点在获取锁时请求失败,也需尝试释放,防止节点恢复后残留锁)。
- 释放锁的指令需带 “唯一 UUID”,确保只释放自己持有的锁(避免误释放他人的锁),指令逻辑通常用 Lua 脚本实现:
if redis.call('get', 'lock_key') == '唯一UUID' then return redis.call('del', 'lock_key') else return 0 end。
三、红锁的核心特性:安全性 vs 可用性
红锁通过多节点冗余,解决了单机 Redis 锁的 “锁丢失” 问题,其核心特性可总结为:
| 特性 | 说明 |
|---|---|
| 安全性 | 只要多数节点(≥3/5)正常,即使少数节点(≤2/5)故障,锁仍能正常获取 / 释放,避免单节点故障导致的锁失效。 |
| 可用性 | 支持少数节点故障(如 5 节点中最多允许 2 个节点宕机),集群仍能提供锁服务,可用性高于单机锁。 |
| 最终一致性 | 释放锁时需向所有节点发起请求,即使部分节点暂时不可达,后续也会因锁过期自动清理,无数据残留。 |
八:redis集群主从复制,有哪些方案,知道吗?

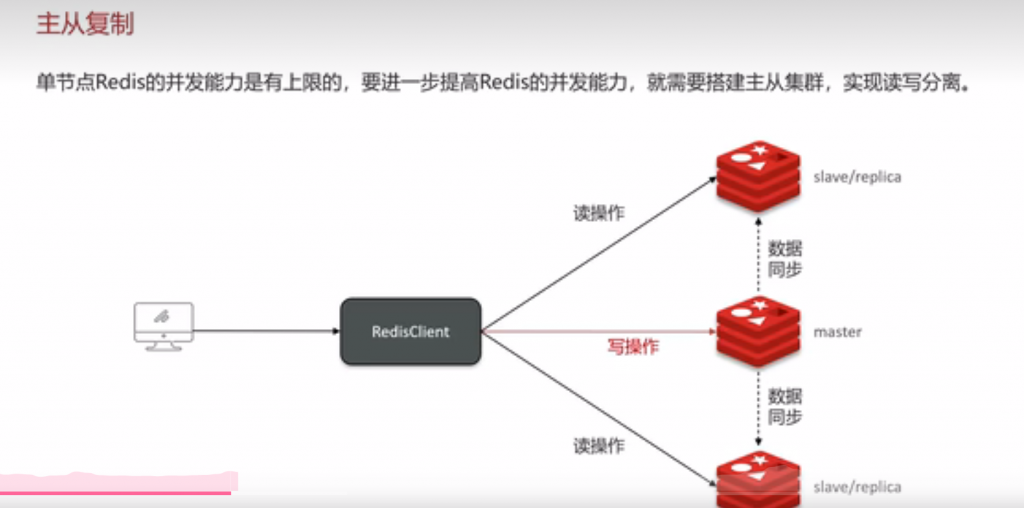
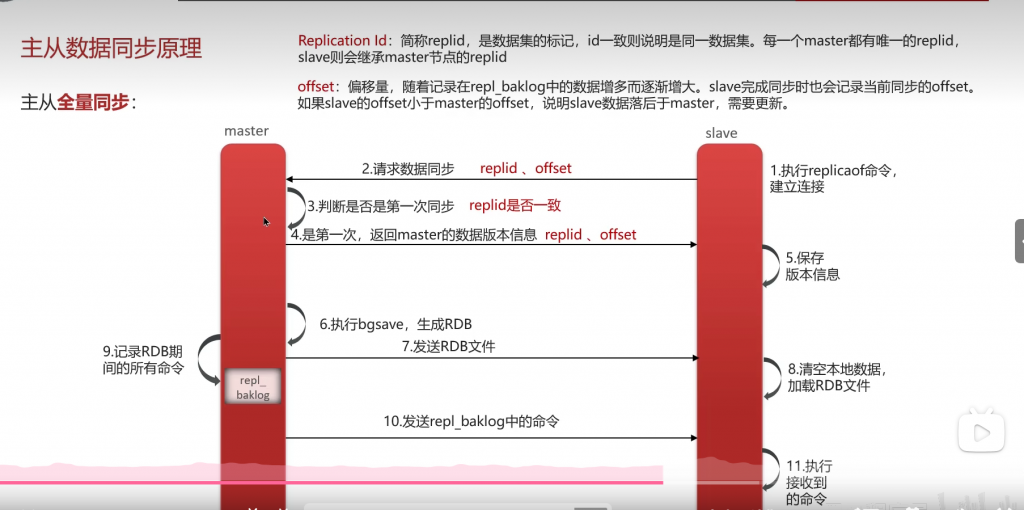
如果是从节点第一次同步,主从repid不一致,主节点同步repid,生成rob文件,从节点会保存数据,如果下次再次同步,只需要在距离上次同步期间的时间内,将新增的数据文件repi-baklog文件中的数据进行恢复即可
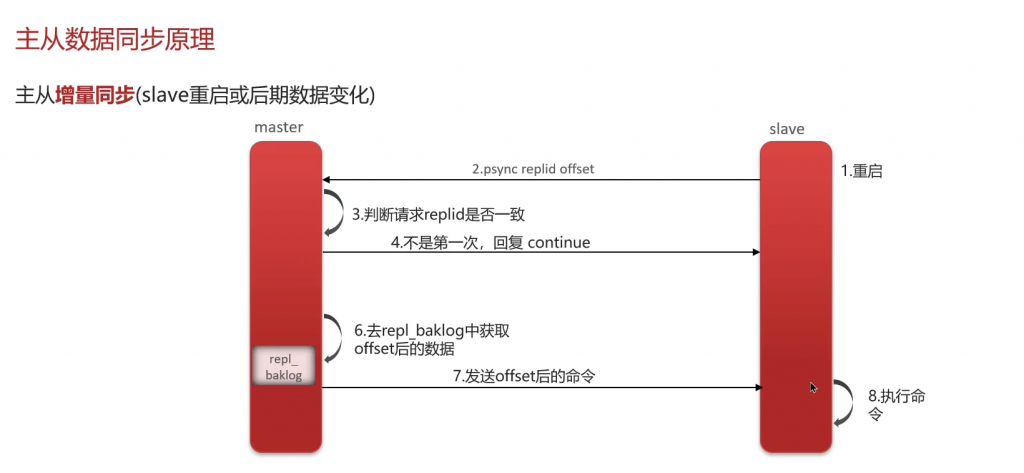
主从数据同步之增量同步:

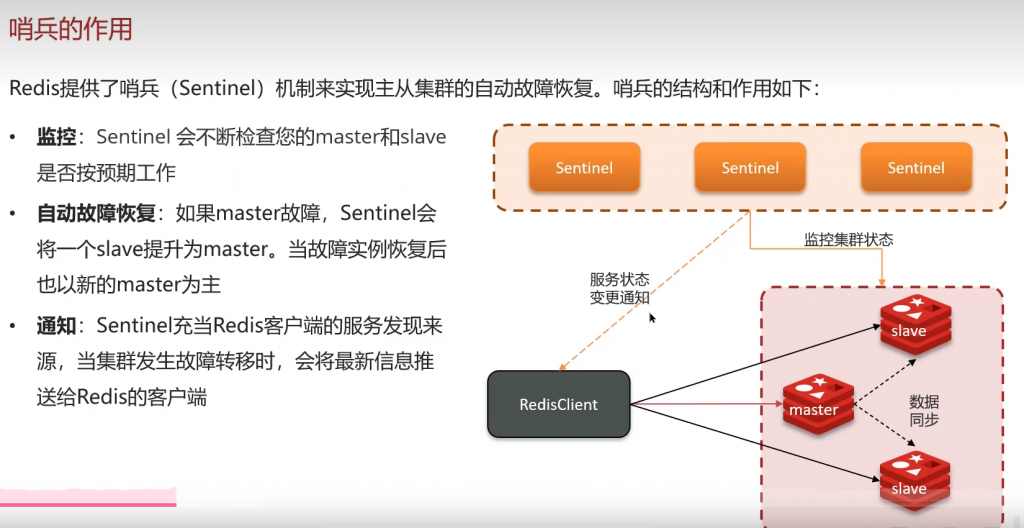
九:哨兵模式:
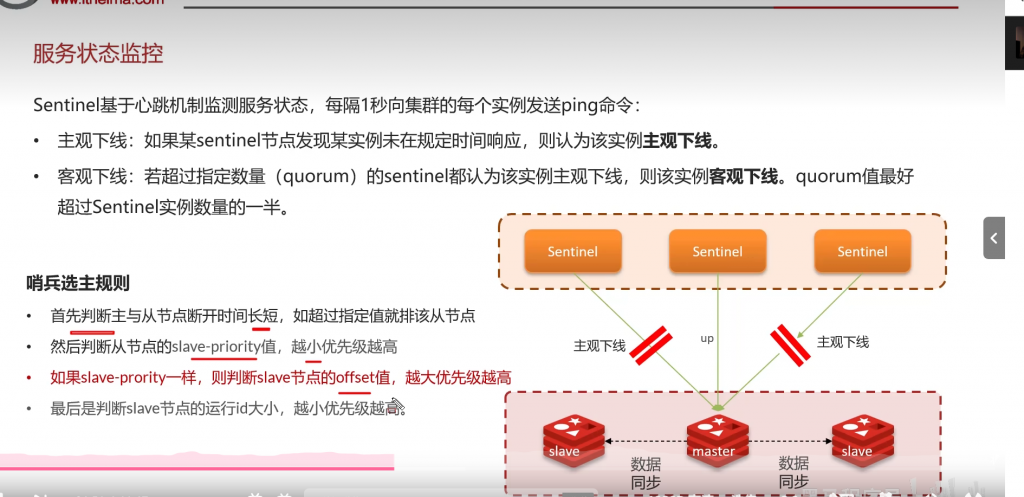
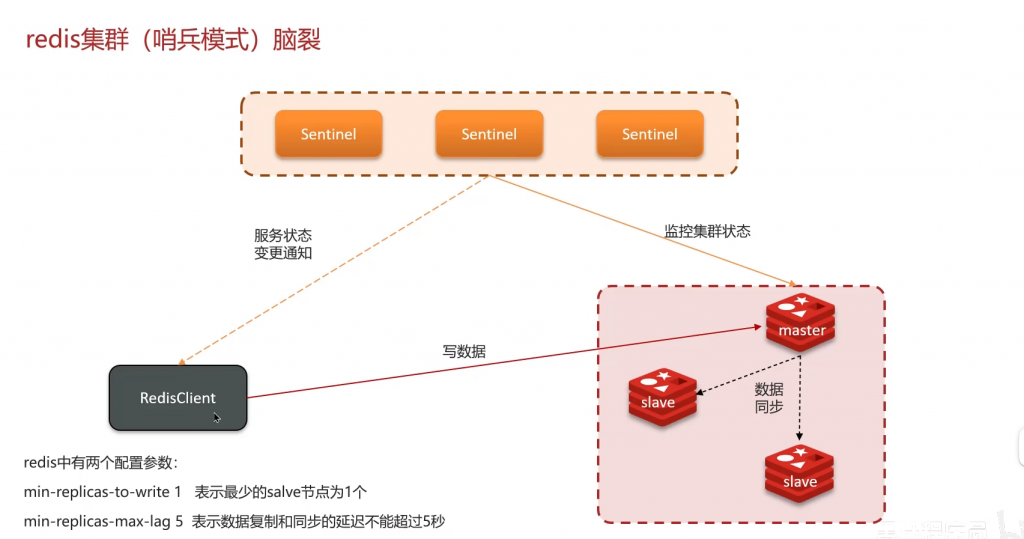

十:分片集群:
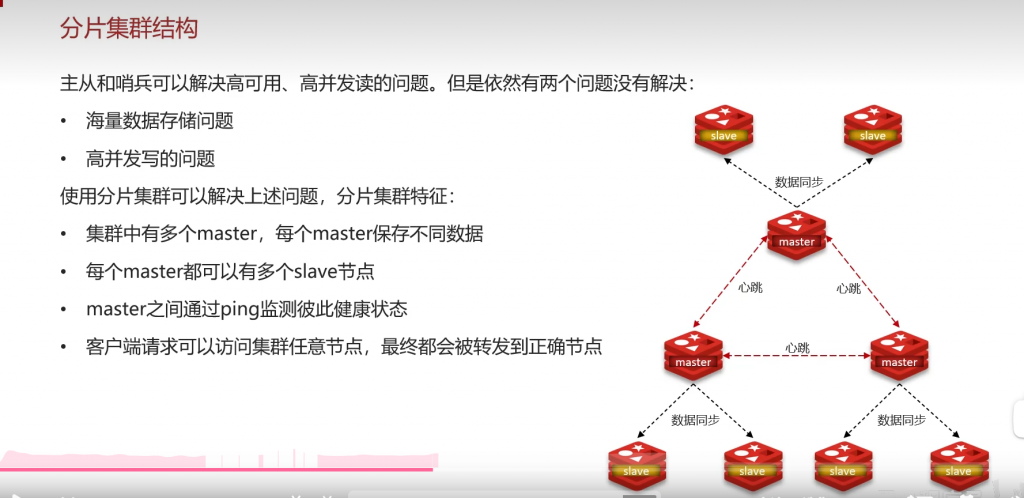


八股:
Mysql:
mysql-优化
问:在mysql中如何定位慢查询?(m1)
方案一:使用工具
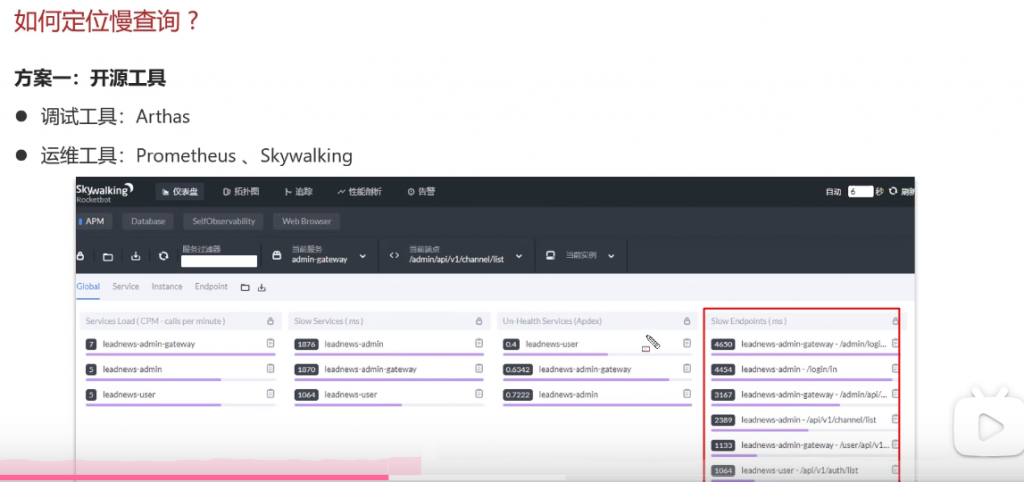
一个是可以使用Arthas,还可以使用Skywalking等
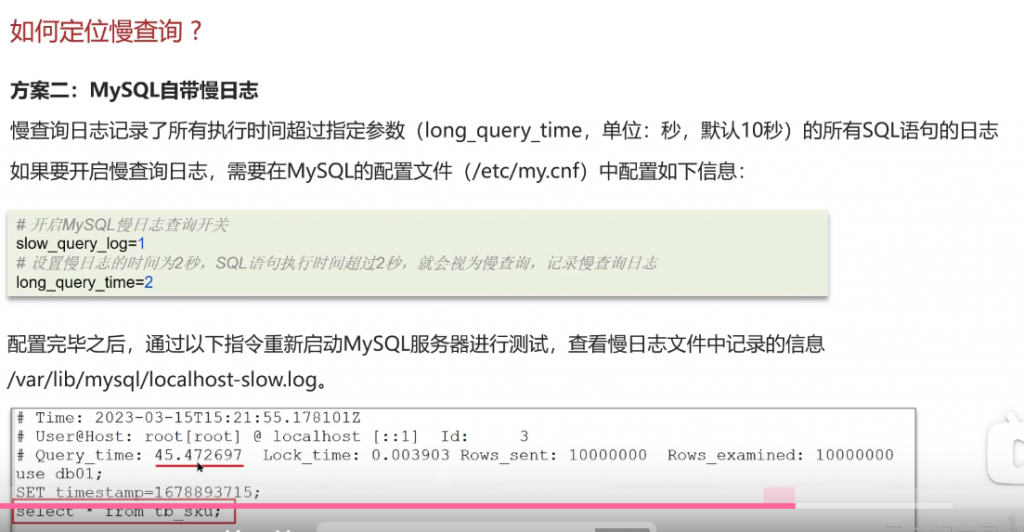
方案二:Mysql自带慢日志


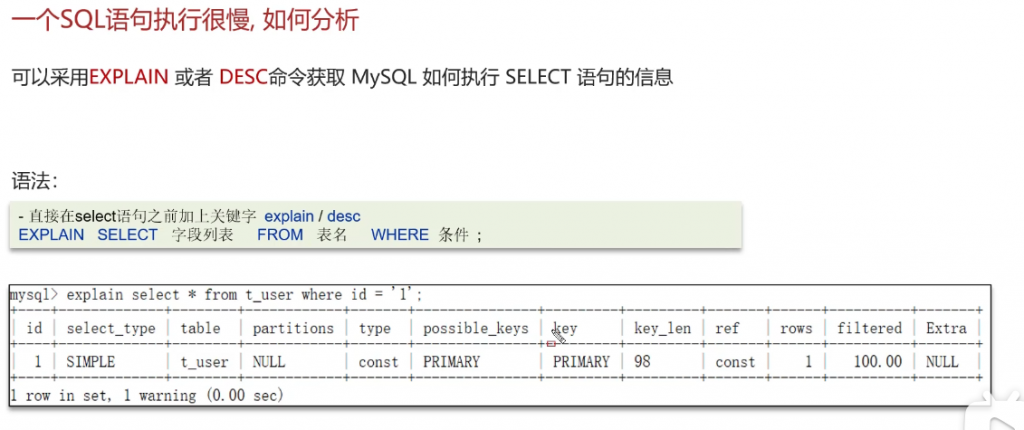
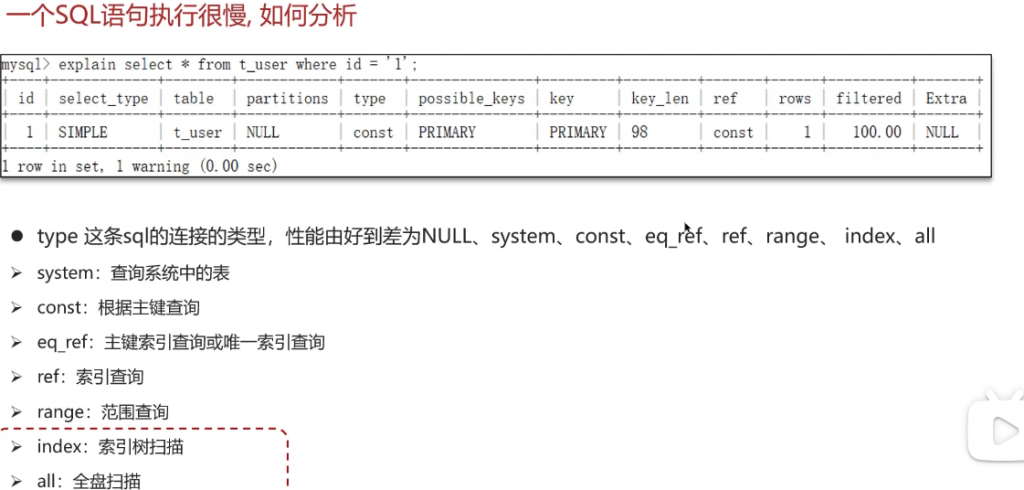
如果一个sql语句执行很慢,如何分析?


问:了解过索引吗,什么是索引?

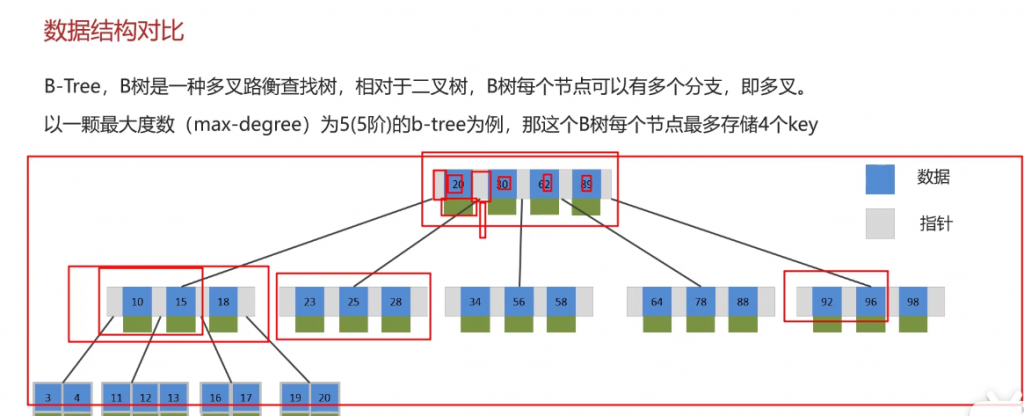
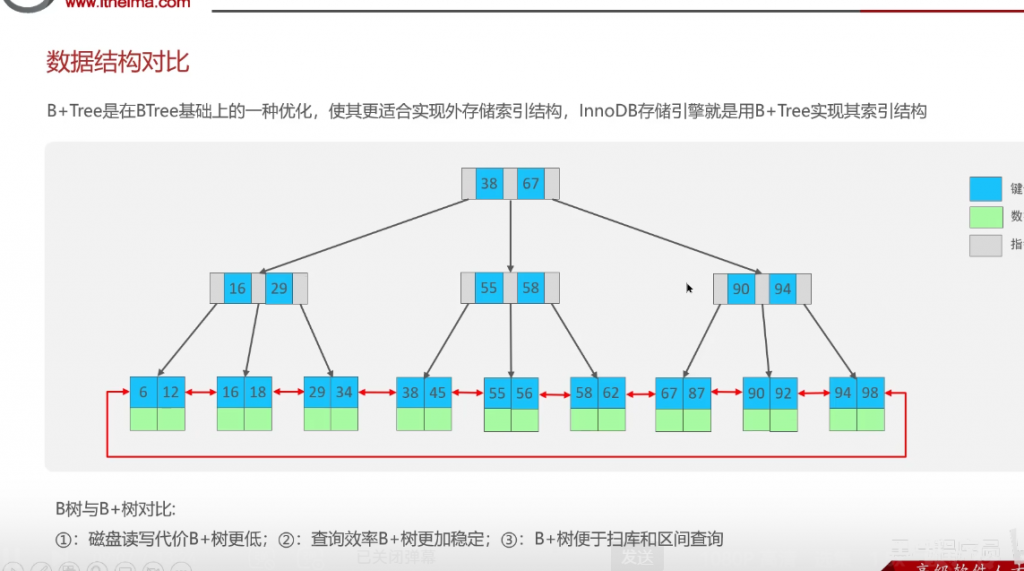
B树和B+树的区别就是B+树的非叶子节点不存储数据,只存储指针,存储和查询压力都比B数小

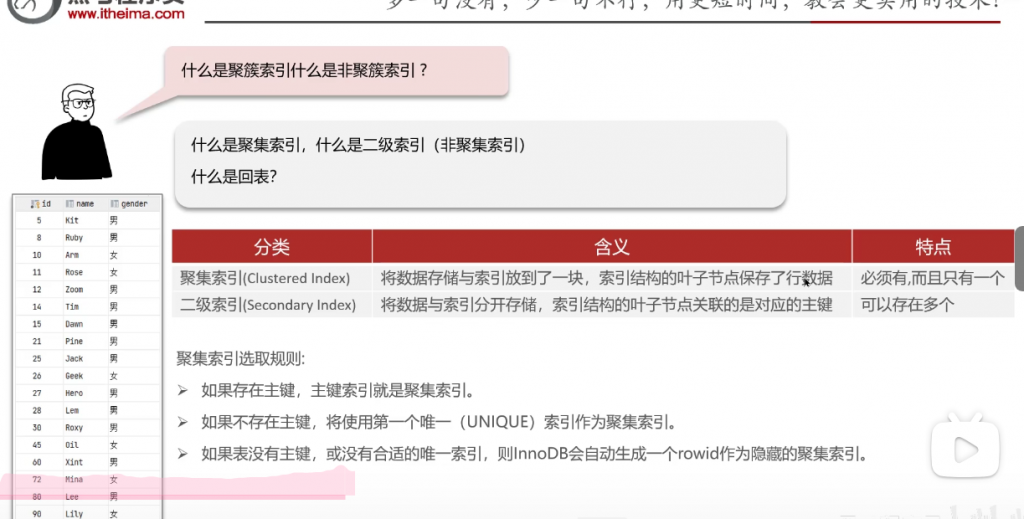
问:什么是聚簇索引,什么是非聚簇索引?
用图像来描绘一下二级索引和聚集索引
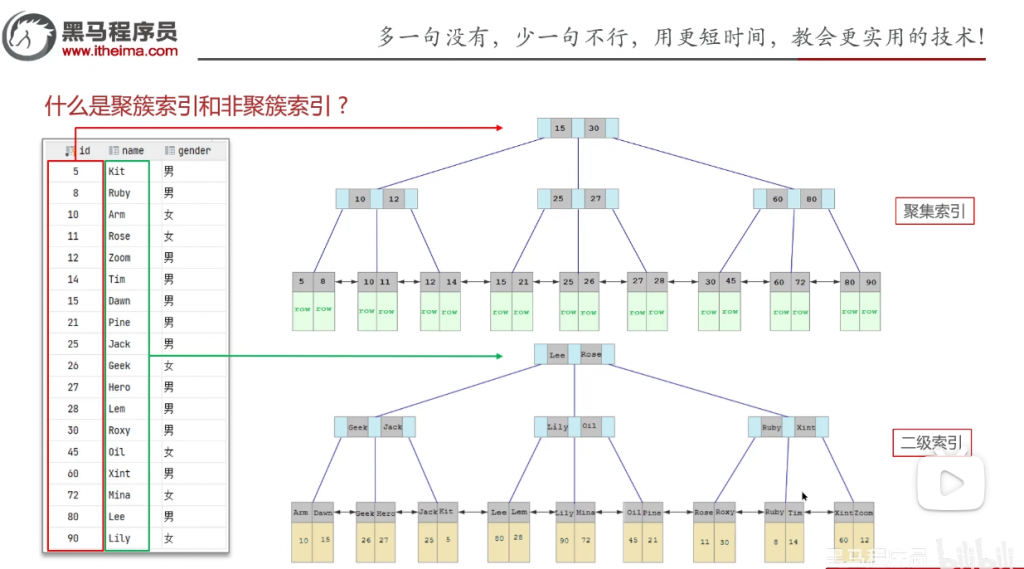
可以看到,聚集索引结构的叶子节点存储的是该行数据
而二级索引存储的是唯一索引(某个索引的值)来用作索引
问:回表查询
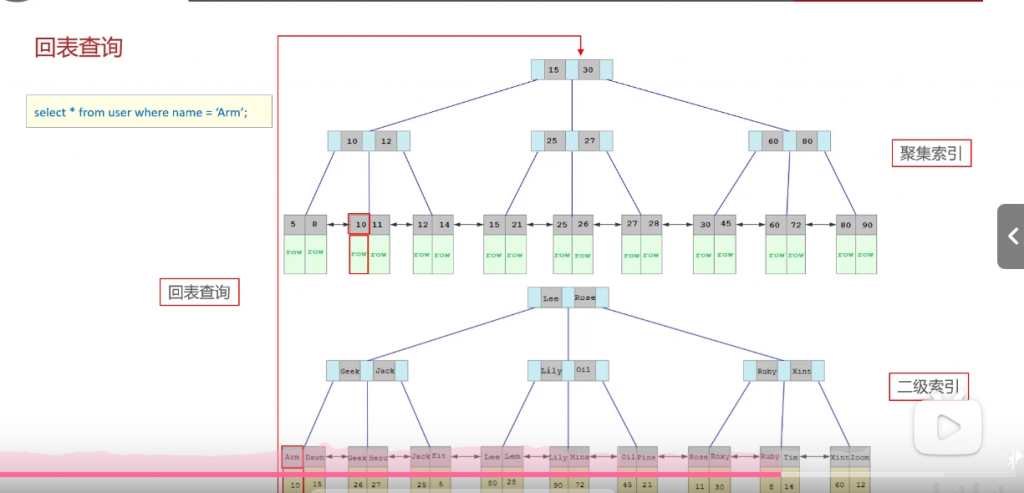
简单的说就是通过二级索引去找到主键值,再去聚集索引里去查整行数据

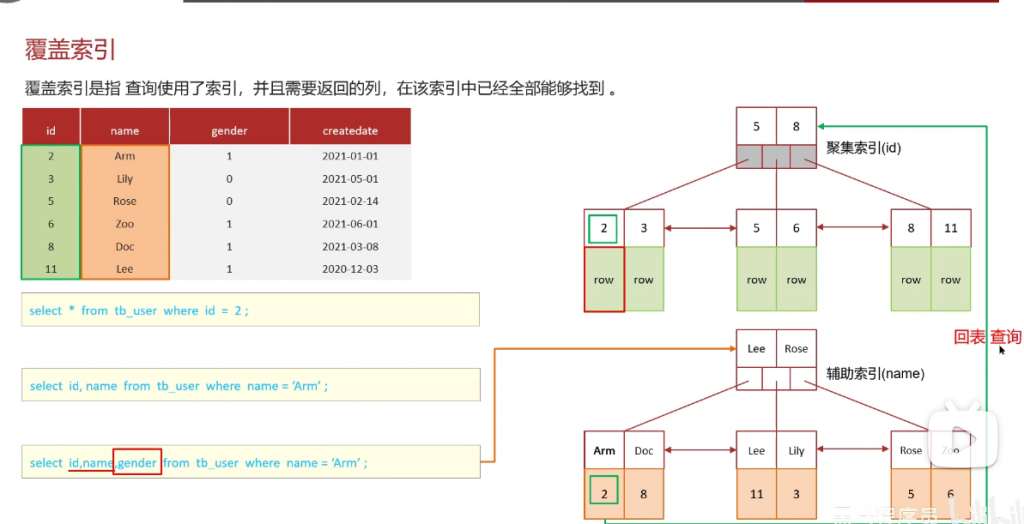
问:知道什么是覆盖索引吗?
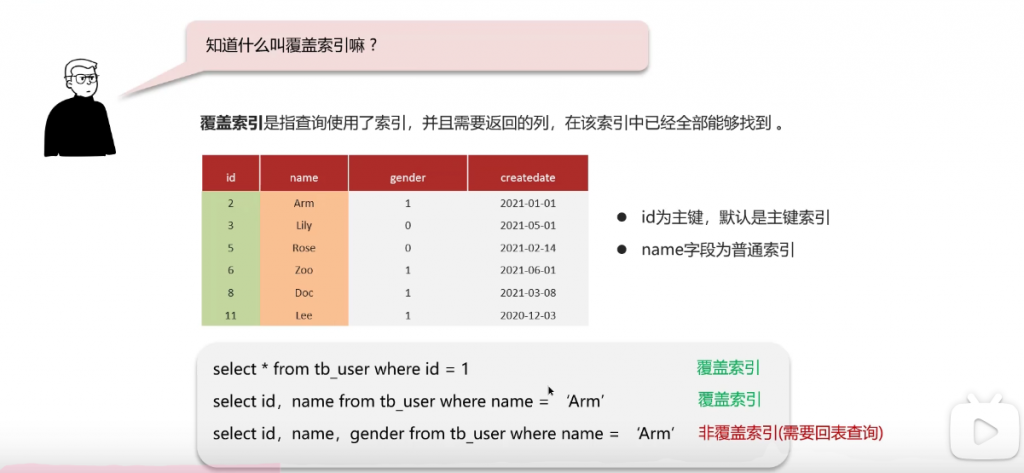
第一个sql由于where条件是id那么就会走聚集索引,查出来全部数据
第二个sql的where条件是name,会走二级索引,但是二级索引还存储了id,而sql的返回值刚好要得是id和name,一次性返回
第三个sql与第二个sql的区别就是sql查询值中多了一个gender,这个性别需要根据id再查一次,需要回表
答:

MYSQL超大分页处理:
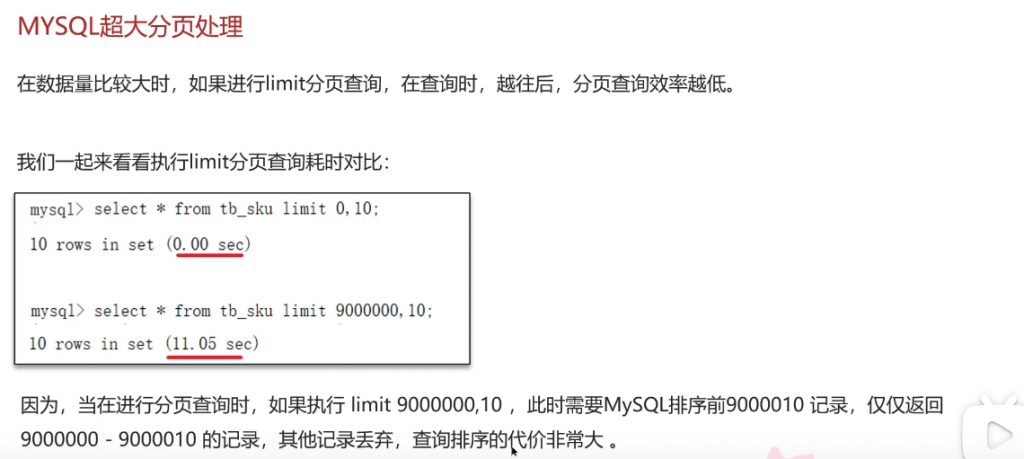
用覆盖索引去解决超大分页的问题
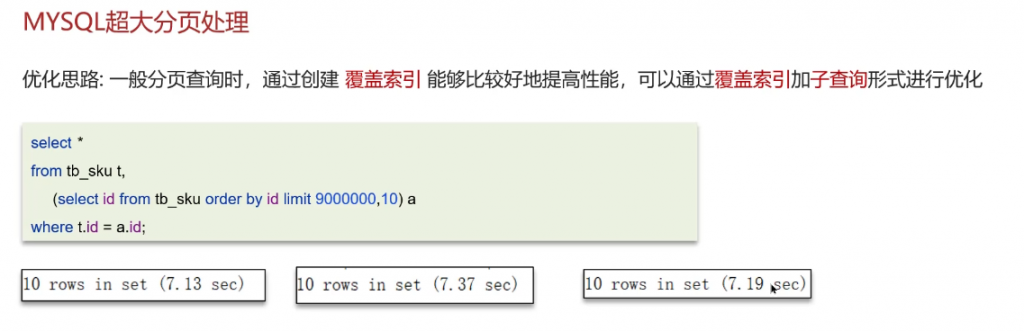

答:

索引创建原则有哪些?



什么情况下索引会失效?
聚合索引中必须遵守最左匹配原则,不能跳着查
正例:

反例:
这个的情况下是下面两个都已经失效,因为违反了最左匹配原则
第三个,只有name符合最左匹配原则,所以虽然使用了索引,
但是只用到了name,未用到address
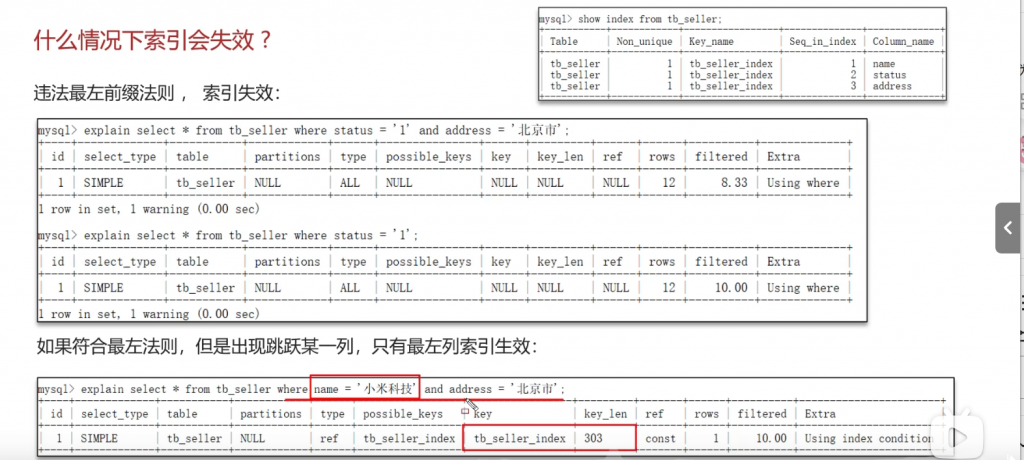
第二种情况:

第三种情况:

第四种情况:

第五种情况:
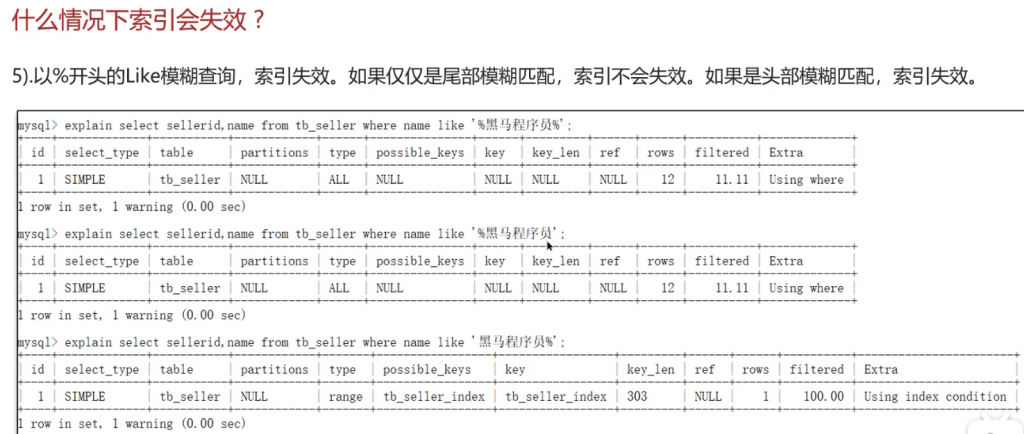
总结:

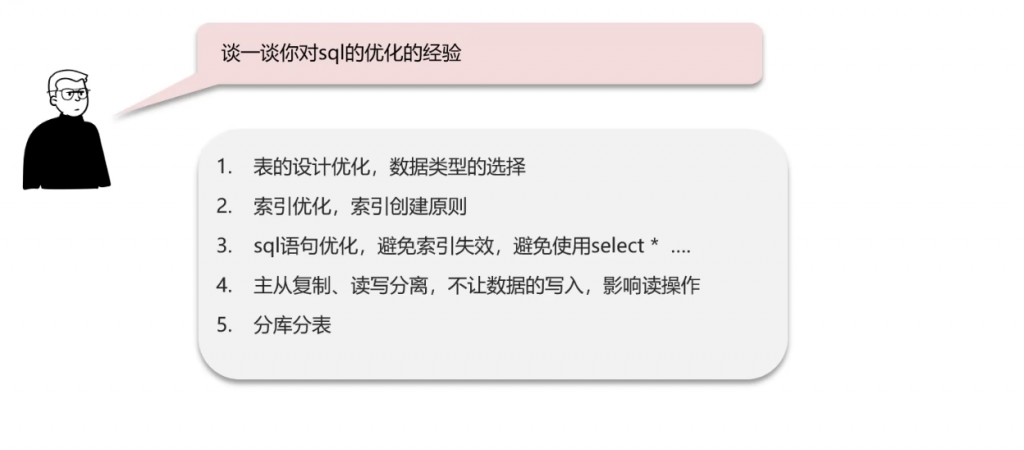
谈一谈你对sql优化的理解:

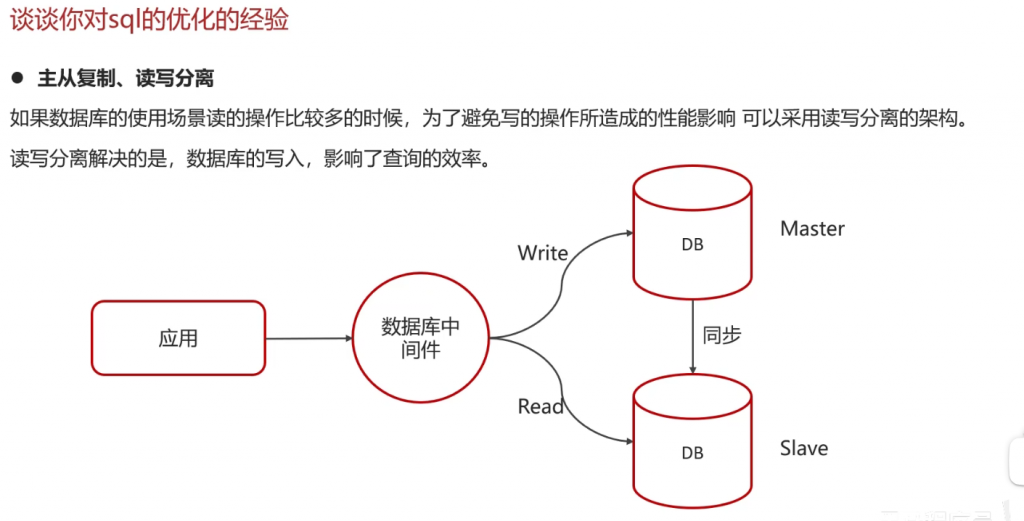

Mysql其他面试题:
什么是事务?

事务特性:ACID


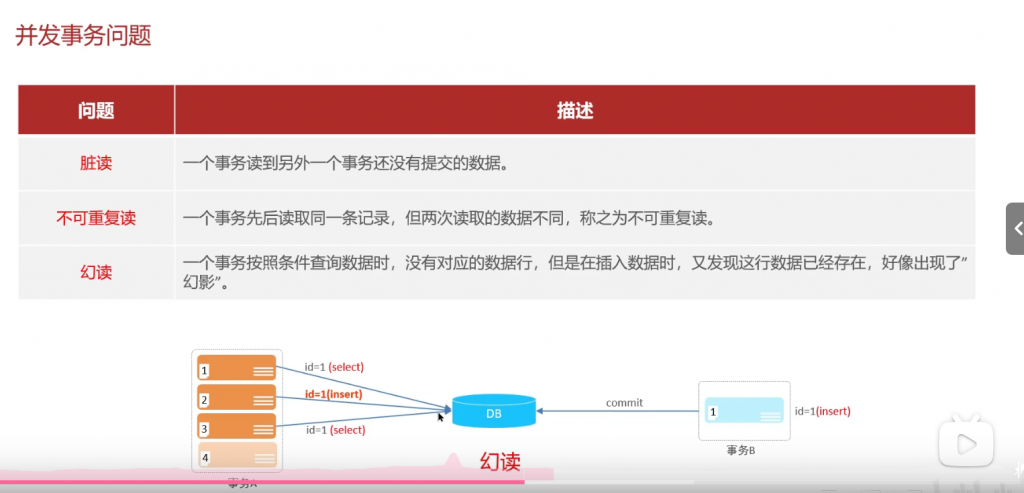
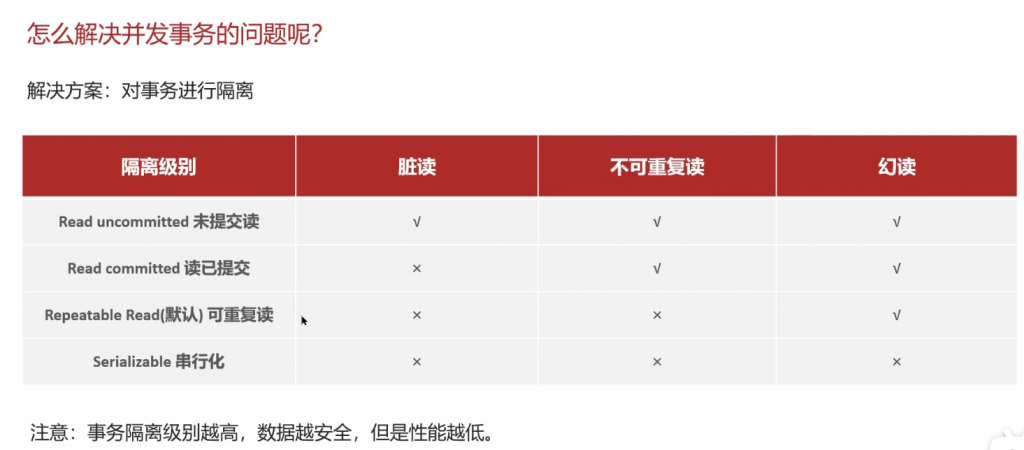
并发事务问题:

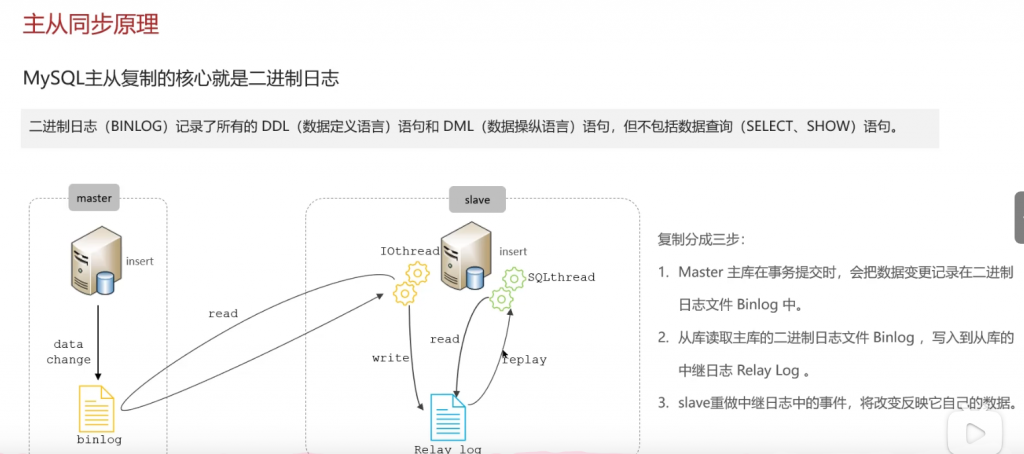
问:Mysql主从同步原理
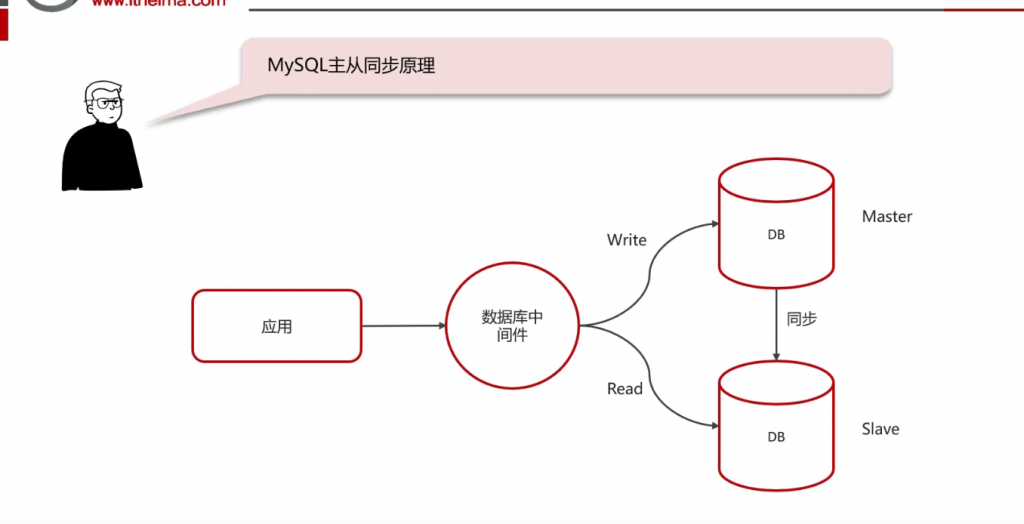
答:


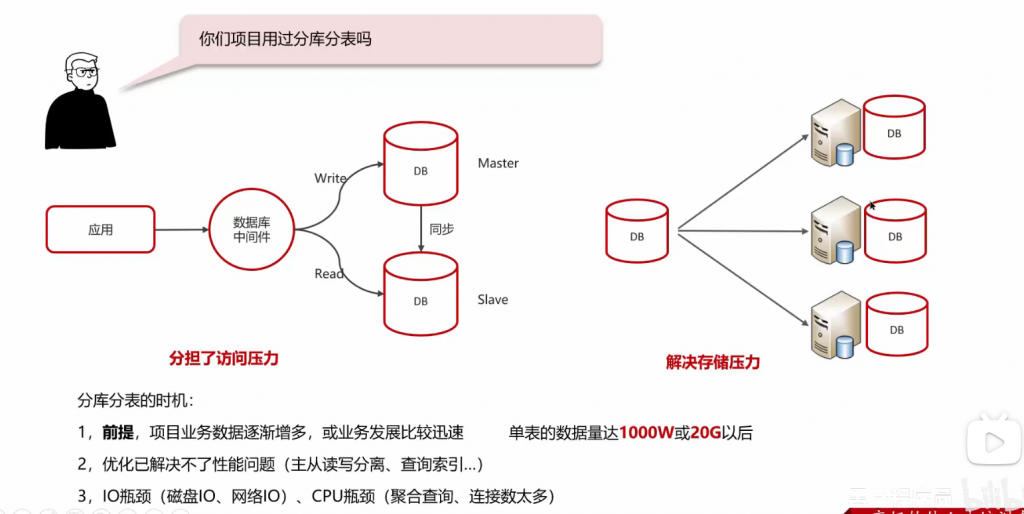
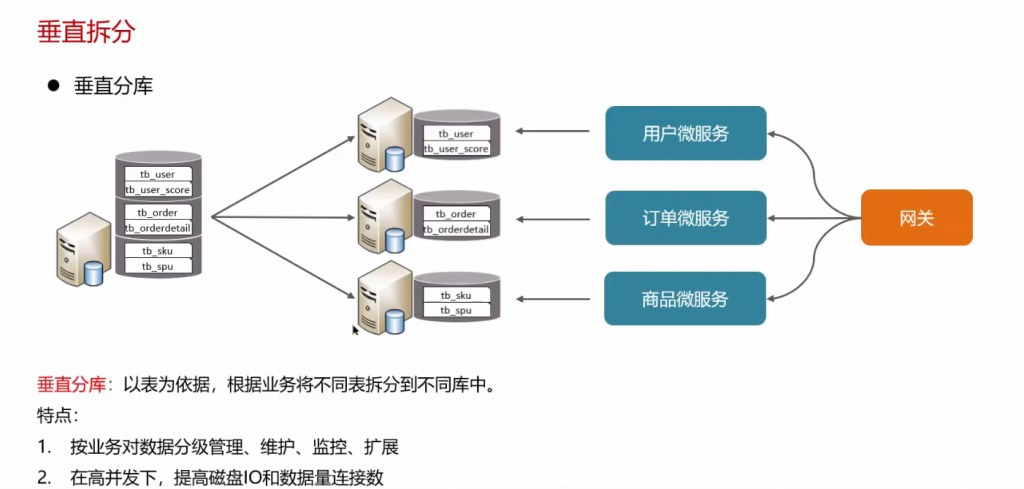
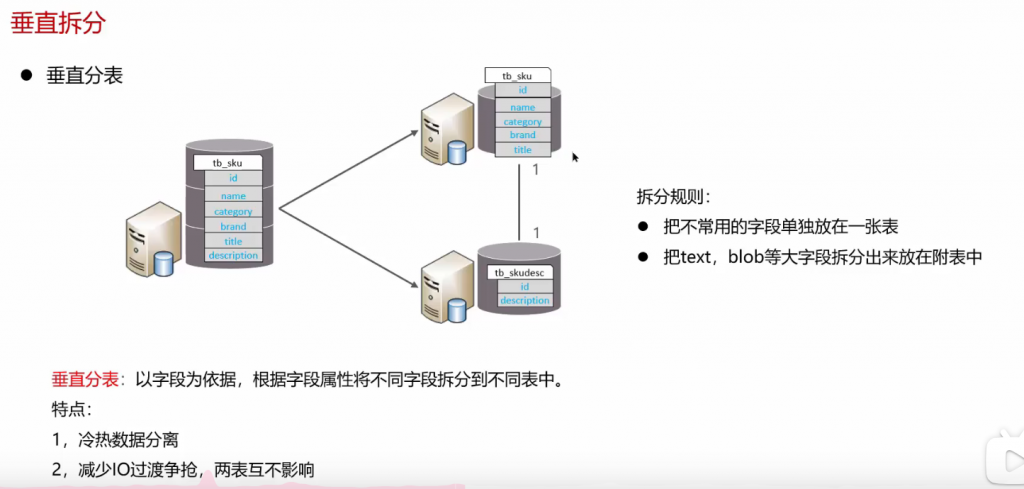
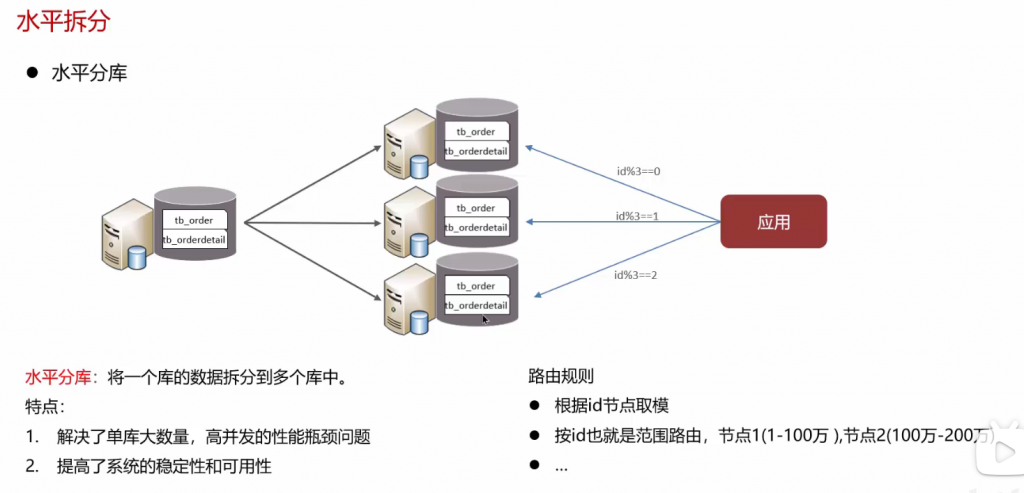
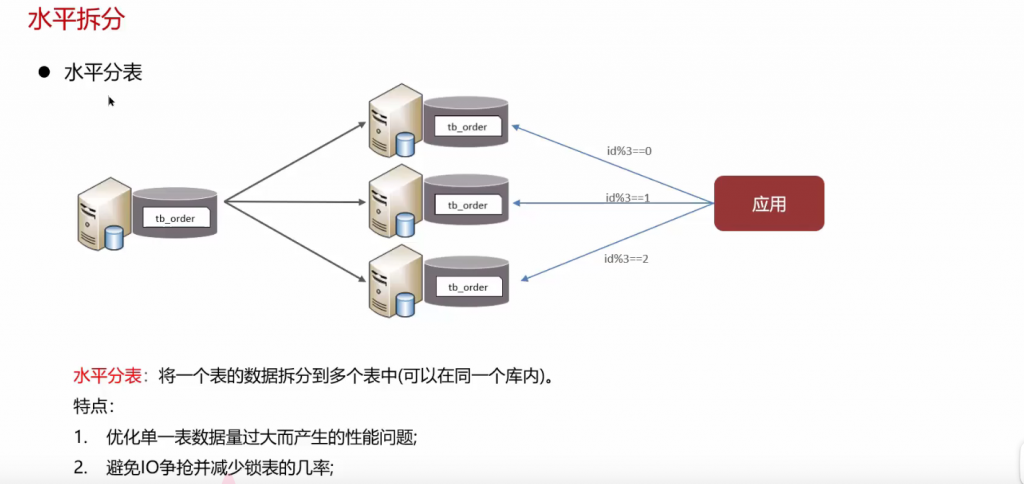
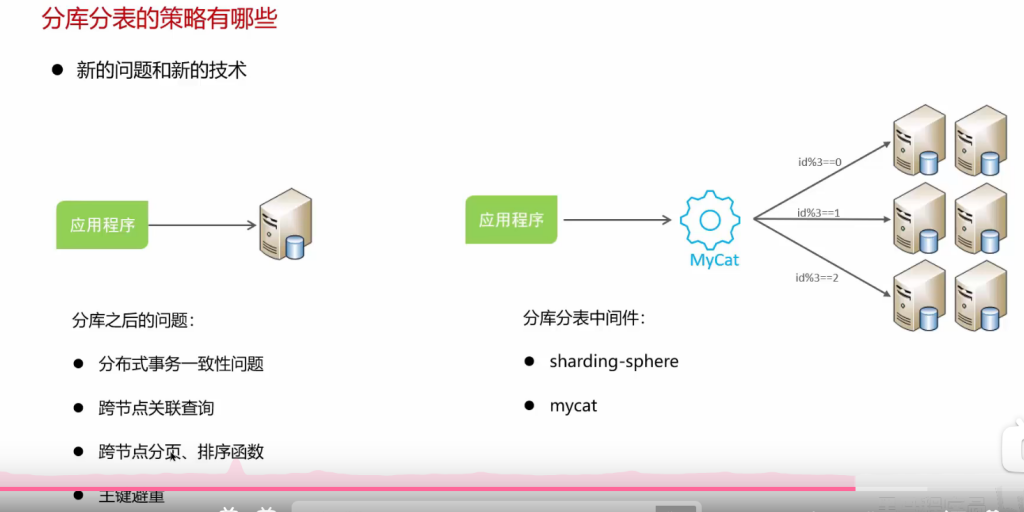
问:分库分表: